array
数组和切片是 Go 语言中常见的数据结构,很多刚刚使用 Go 的开发者往往会混淆这两个概念。数组作为最常见的集合在编程语言中是非常重要的,除了数组之外,Go 语言引入了另一个概念 — 切片,切片与数组有一些类似,但是它们的不同导致了使用上的巨大差别。我们在这一节中会从 Go 语言的编译期间运行时来介绍数组的底层实现原理,其中会包括数组的初始化、访问和赋值几种常见操作。
概述
数组是由相同类型元素的集合组成的数据结构,计算机会为数组分配一块连续的内存来保存其中的元素,我们可以利用数组中元素的索引快速访问特定元素,常见的数组大多都是一维的线性数组,而多维数组在数值和图形计算领域却有比较常见的应用。
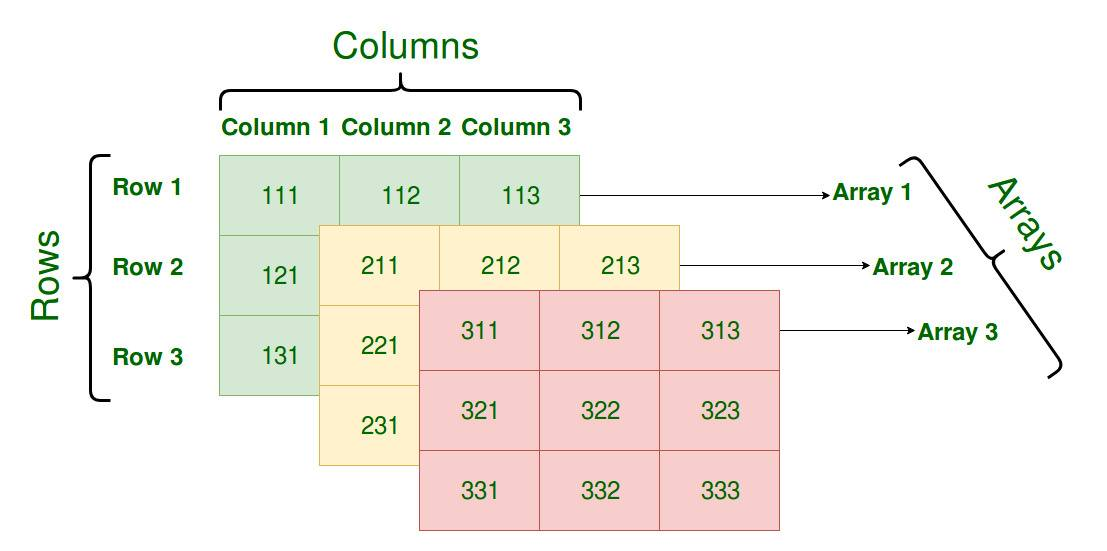
数组作为一种基本的数据类型,我们通常会从两个维度描述数组,也就是数组中存储的元素类型和数组最大能存储的元素个数,在 Go 语言中我们往往会使用如下所示的方式来表示数组类型:
1
2
|
[10]int
[200]interface{}
|
Go 语言数组在初始化之后大小就无法改变,存储元素类型相同、但是大小不同的数组类型在 Go 语言看来也是完全不同的,只有两个条件都相同才是同一类型。
1
2
3
4
5
6
7
8
9
|
func NewArray(elem *Type, bound int64)*Type {
if bound < 0 {
Fatalf("NewArray: invalid bound %v", bound)
}
t := New(TARRAY)
t.Extra = &Array{Elem: elem, Bound: bound}
t.SetNotInHeap(elem.NotInHeap())
return t
}
|
编译期间的数组类型是由上述的 cmd/compile/internal/types.NewArray 函数生成的,该类型包含两个字段,分别是元素类型 Elem 和数组的大小 Bound,这两个字段共同构成了数组类型,而当前数组是否应该在堆栈中初始化也在编译期就确定了。
初始化
Go 语言的数组有两种不同的创建方式,一种是显式的指定数组大小,另一种是使用 […]T 声明数组,Go 语言会在编译期间通过源代码推导数组的大小:
1
2
|
arr1 := [3]int{1, 2, 3}
arr2 := [...]int{1, 2, 3}
|
上述两种声明方式在运行期间得到的结果是完全相同的,后一种声明方式在编译期间就会被转换成前一种,这也就是编译器对数组大小的推导,下面我们来介绍编译器的推导过程。
上限推导
两种不同的声明方式会导致编译器做出完全不同的处理,如果我们使用第一种方式 [10]T,那么变量的类型在编译进行到类型检查阶段就会被提取出来,随后使用 cmd/compile/internal/types.NewArray创建包含数组大小的 cmd/compile/internal/types.Array 结构体。
当我们使用 [...]T 的方式声明数组时,编译器会在的 cmd/compile/internal/gc.typecheckcomplit 函数中对该数组的大小进行推导:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func typecheckcomplit(n *Node) (res*Node) {
...
if n.Right.Op == OTARRAY && n.Right.Left != nil && n.Right.Left.Op == ODDD {
n.Right.Right = typecheck(n.Right.Right, ctxType)
if n.Right.Right.Type == nil {
n.Type = nil
return n
}
elemType := n.Right.Right.Type
length := typecheckarraylit(elemType, -1, n.List.Slice(), "array literal")
n.Op = OARRAYLIT
n.Type = types.NewArray(elemType, length)
n.Right = nil
return n
}
...
switch t.Etype {
case TARRAY:
typecheckarraylit(t.Elem(), t.NumElem(), n.List.Slice(), "array literal")
n.Op = OARRAYLIT
n.Right = nil
}
}
|
这个删减后的 cmd/compile/internal/gc.typecheckcomplit 会调用 cmd/compile/internal/gc.typecheckarraylit 通过遍历元素的方式来计算数组中元素的数量。
所以我们可以看出 [...]T{1, 2, 3} 和 [3]T{1, 2, 3} 在运行时是完全等价的,[...]T 这种初始化方式也只是 Go 语言为我们提供的一种语法糖,当我们不想计算数组中的元素个数时可以通过这种方法减少一些工作量。
语句转换
对于一个由字面量组成的数组,根据数组元素数量的不同,编译器会在负责初始化字面量的 cmd/compile/internal/gc.anylit 函数中做两种不同的优化:
- 当元素数量小于或者等于 4 个时,会直接将数组中的元素放置在栈上;
- 当元素数量大于 4 个时,会将数组中的元素放置到静态区并在运行时取出;
1
2
3
4
5
6
7
8
9
10
11
12
|
func anylit(n *Node, var_*Node, init *Nodes) {
t := n.Type
switch n.Op {
case OSTRUCTLIT, OARRAYLIT:
if n.List.Len() > 4 {
...
}
fixedlit(inInitFunction, initKindLocalCode, n, var_, init)
...
}
}
|
当数组的元素小于或者等于四个时,cmd/compile/internal/gc.fixedlit 会负责在函数编译之前将 [3]{1, 2, 3} 转换成更加原始的语句:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func fixedlit(ctxt initContext, kind initKind, n *Node, var_*Node, init *Nodes) {
var splitnode func(*Node) (a *Node, value*Node)
...
for _, r := range n.List.Slice() {
a, value := splitnode(r)
a = nod(OAS, a, value)
a = typecheck(a, ctxStmt)
switch kind {
case initKindStatic:
genAsStatic(a)
case initKindLocalCode:
a = orderStmtInPlace(a, map[string][]*Node{})
a = walkstmt(a)
init.Append(a)
}
}
}
|
当数组中元素的个数小于或者等于四个并且 cmd/compile/internal/gc.fixedlit 函数接收的 kind 是 initKindLocalCode 时,上述代码会将原有的初始化语句 [3]int{1, 2, 3} 拆分成一个声明变量的表达式和几个赋值表达式,这些表达式会完成对数组的初始化:
1
2
3
4
|
var arr [3]int
arr[0] = 1
arr[1] = 2
arr[2] = 3
|
但是如果当前数组的元素大于四个,cmd/compile/internal/gc.anylit 会先获取一个唯一的 staticname,然后调用 cmd/compile/internal/gc.fixedlit 函数在静态存储区初始化数组中的元素并将临时变量赋值给数组:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func anylit(n *Node, var_*Node, init *Nodes) {
t := n.Type
switch n.Op {
case OSTRUCTLIT, OARRAYLIT:
if n.List.Len() > 4 {
vstat := staticname(t)
vstat.Name.SetReadonly(true)
fixedlit(inNonInitFunction, initKindStatic, n, vstat, init)
a := nod(OAS, var_, vstat)
a = typecheck(a, ctxStmt)
a = walkexpr(a, init)
init.Append(a)
break
}
...
}
}
|
假设代码需要初始化 [5]int{1, 2, 3, 4, 5},那么我们可以将上述过程理解成以下的伪代码:
1
2
3
4
5
6
7
|
var arr [5]int
statictmp_0[0] = 1
statictmp_0[1] = 2
statictmp_0[2] = 3
statictmp_0[3] = 4
statictmp_0[4] = 5
arr = statictmp_0
|
总结起来,在不考虑逃逸分析的情况下,如果数组中元素的个数小于或者等于 4 个,那么所有的变量会直接在栈上初始化,如果数组元素大于 4 个,变量就会在静态存储区初始化然后拷贝到栈上,这些转换后的代码才会继续进入中间代码生成和机器码生成两个阶段,最后生成可以执行的二进制文件。
访问和赋值
无论是在栈上还是静态存储区,数组在内存中都是一连串的内存空间,我们通过指向数组开头的指针、元素的数量以及元素类型占的空间大小表示数组。如果我们不知道数组中元素的数量,访问时可能发生越界;而如果不知道数组中元素类型的大小,就没有办法知道应该一次取出多少字节的数据,无论丢失了哪个信息,我们都无法知道这片连续的内存空间到底存储了什么数据:

数组访问越界是非常严重的错误,Go 语言中可以在编译期间的静态类型检查判断数组越界,cmd/compile/internal/gc.typecheck1 会验证访问数组的索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
func typecheck1(n *Node, top int) (res*Node) {
switch n.Op {
case OINDEX:
ok |= ctxExpr
l := n.Left // array
r := n.Right // index
switch n.Left.Type.Etype {
case TSTRING, TARRAY, TSLICE:
...
if n.Right.Type != nil && !n.Right.Type.IsInteger() {
yyerror("non-integer array index %v", n.Right)
break
}
if !n.Bounded() && Isconst(n.Right, CTINT) {
x := n.Right.Int64()
if x < 0 {
yyerror("invalid array index %v (index must be non-negative)", n.Right)
} else if n.Left.Type.IsArray() && x >= n.Left.Type.NumElem() {
yyerror("invalid array index %v (out of bounds for %d-element array)", n.Right, n.Left.Type.NumElem())
}
}
}
...
}
}
|
- 访问数组的索引是非整数时,报错 “non-integer array index %v”;
- 访问数组的索引是负数时,报错 “invalid array index %v (index must be non-negative)";
- 访问数组的索引越界时,报错 “invalid array index %v (out of bounds for %d-element array)";
数组和字符串的一些简单越界错误都会在编译期间发现,例如:直接使用整数或者常量访问数组;但是如果使用变量去访问数组或者字符串时,编译器就无法提前发现错误,我们需要 Go 语言运行时阻止不合法的访问:
1
2
|
arr[4]: invalid array index 4 (out of bounds for 3-element array)
arr[i]: panic: runtime error: index out of range [4] with length 3
|
Go 语言运行时在发现数组、切片和字符串的越界操作会由运行时的 runtime.panicIndex 和 runtime.goPanicIndex 触发程序的运行时错误并导致崩溃退出:
1
2
3
4
|
TEXT runtime·panicIndex(SB),NOSPLIT,$0-8
MOVL AX, x+0(FP)
MOVL CX, y+4(FP)
JMP runtime·goPanicIndex(SB)
|
1
2
3
4
|
func goPanicIndex(x int, y int) {
panicCheck1(getcallerpc(), "index out of range")
panic(boundsError{x: int64(x), signed: true, y: y, code: boundsIndex})
}
|
当数组的访问操作 OINDEX 成功通过编译器的检查后,会被转换成几个 SSA 指令,假设我们有如下所示的 Go 语言代码,通过如下的方式进行编译会得到 ssa.html 文件:
1
2
3
4
5
6
7
8
|
package check
func outOfRange() int {
arr := [3]int{1, 2, 3}
i := 4
elem := arr[i]
return elem
}
|
1
2
|
$ GOSSAFUNC=outOfRange go build array.go
dumped SSA to ./ssa.html
|
start 阶段生成的 SSA 代码就是优化之前的第一版中间代码,下面展示的部分是 elem := arr[i] 对应的中间代码,在这段中间代码中我们发现 Go 语言为数组的访问操作生成了判断数组上限的指令 IsInBounds 以及当条件不满足时触发程序崩溃的 PanicBounds 指令:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
b1:
...
v22 (6) = LocalAddr <*[3]int> {arr} v2 v20
v23 (6) = IsInBounds <bool> v21 v11
If v23 → b2 b3 (likely) (6)
b2: ← b1-
v26 (6) = PtrIndex <*int> v22 v21
v27 (6) = Copy <mem> v20
v28 (6) = Load <int> v26 v27 (elem[int])
...
Ret v30 (+7)
b3: ← b1-
v24 (6) = Copy <mem> v20
v25 (6) = PanicBounds <mem> [0] v21 v11 v24
Exit v25 (6)
|
编译器会将 PanicBounds 指令转换成上面提到的 runtime.panicIndex 函数,当数组下标没有越界时,编译器会先获取数组的内存地址和访问的下标、利用 PtrIndex 计算出目标元素的地址,最后使用 Load 操作将指针中的元素加载到内存中。
当然只有当编译器无法对数组下标是否越界无法做出判断时才会加入 PanicBounds 指令交给运行时进行判断,在使用字面量整数访问数组下标时会生成非常简单的中间代码,当我们将上述代码中的 arr[i] 改成 arr[2] 时,就会得到如下所示的代码:
1
2
3
4
5
6
|
b1:
...
v21 (5) = LocalAddr <*[3]int> {arr} v2 v20
v22 (5) = PtrIndex <*int> v21 v14
v23 (5) = Load <int> v22 v20 (elem[int])
...
|
Go 语言对于数组的访问还是有着比较多的检查的,它不仅会在编译期间提前发现一些简单的越界错误并插入用于检测数组上限的函数调用,还会在运行期间通过插入的函数保证不会发生越界。
数组的赋值和更新操作 a[i] = 2 也会生成 SSA 生成期间计算出数组当前元素的内存地址,然后修改当前内存地址的内容,这些赋值语句会被转换成如下所示的 SSA 代码:
1
2
3
4
5
6
|
b1:
...
v21 (5) = LocalAddr <*[3]int> {arr} v2 v19
v22 (5) = PtrIndex <*int> v21 v13
v23 (5) = Store <mem> {int} v22 v20 v19
...
|
赋值的过程中会先确定目标数组的地址,再通过 PtrIndex 获取目标元素的地址,最后使用 Store 指令将数据存入地址中,从上面的这些 SSA 代码中我们可以看出 上述数组寻址和赋值都是在编译阶段完成的,没有运行时的参与。
小结
数组是 Go 语言中重要的数据结构,了解它的实现能够帮助我们更好地理解这门语言,通过对其实现的分析,我们知道了对数组的访问和赋值需要同时依赖编译器和运行时,它的大多数操作在编译期间都会转换成直接读写内存,在中间代码生成期间,编译器还会插入运行时方法 runtime.panicIndex 调用防止发生越界错误。
slice
上一节介绍的数组在 Go 语言中没那么常用,更常用的数据结构是切片,即动态数组,其长度并不固定,我们可以向切片中追加元素,它会在容量不足时自动扩容。
在 Go 语言中,切片类型的声明方式与数组有一些相似,不过由于切片的长度是动态的,所以声明时只需要指定切片中的元素类型:
从切片的定义我们能推测出,切片在编译期间的生成的类型只会包含切片中的元素类型,即 int 或者 interface{} 等。cmd/compile/internal/types.NewSlice 就是编译期间用于创建切片类型的函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func NewSlice(elem *Type)*Type {
if t := elem.Cache.slice; t != nil {
if t.Elem() != elem {
Fatalf("elem mismatch")
}
return t
}
t := New(TSLICE)
t.Extra = Slice{Elem: elem}
elem.Cache.slice = t
return t
}
|
上述方法返回结构体中的 Extra 字段是一个只包含切片内元素类型的结构,也就是说切片内元素的类型都是在编译期间确定的,编译器确定了类型之后,会将类型存储在 Extra 字段中帮助程序在运行时动态获取。
数据结构
编译期间的切片是 cmd/compile/internal/types.Slice 类型的,但是在运行时切片可以由如下的 reflect.SliceHeader 结构体表示,其中:
- Data 是指向数组的指针;
- Len 是当前切片的长度;
- Cap 是当前切片的容量,即 Data 数组的大小:
1
2
3
4
5
|
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
|
Data 是一片连续的内存空间,这片内存空间可以用于存储切片中的全部元素,数组中的元素只是逻辑上的概念,底层存储其实都是连续的,所以我们可以将切片理解成一片连续的内存空间加上长度与容量的标识。
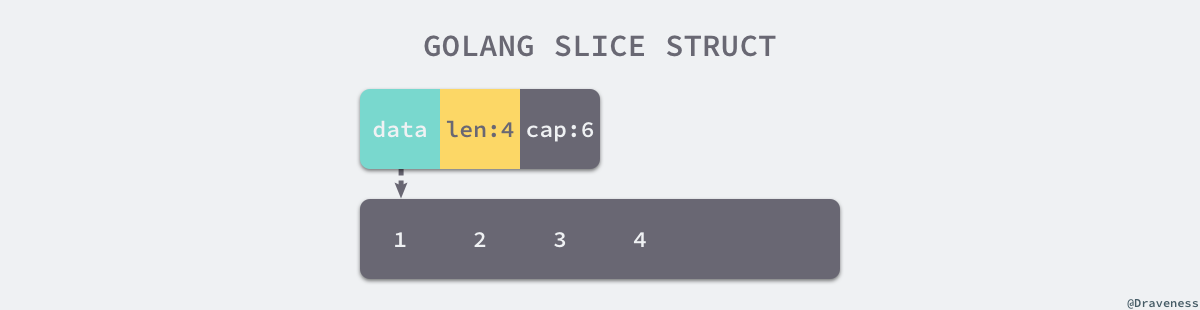
从上图中,我们会发现切片与数组的关系非常密切,切片引入了一个抽象层,提供了对数组中部分连续片段的引用,而作为数组的引用,我们可以在运行区间可以修改它的长度和范围。当切片底层的数组长度不足时就会触发扩容,切片指向的数组可能会发生变化,不过在上层看来切片是没有变化的,上层只需要与切片打交道不需要关心数组的变化。
我们在上一节介绍过编译器在编译期间简化了获取数组大小、读写数组中的元素等操作:因为数组的内存固定且连续,多数操作都会直接读写内存的特定位置。slice的底层数组是可以被多个 slice 同时指向的,因此对一个 slice 的元素进行操作是有可能影响到其他 slice 的。
直接声明
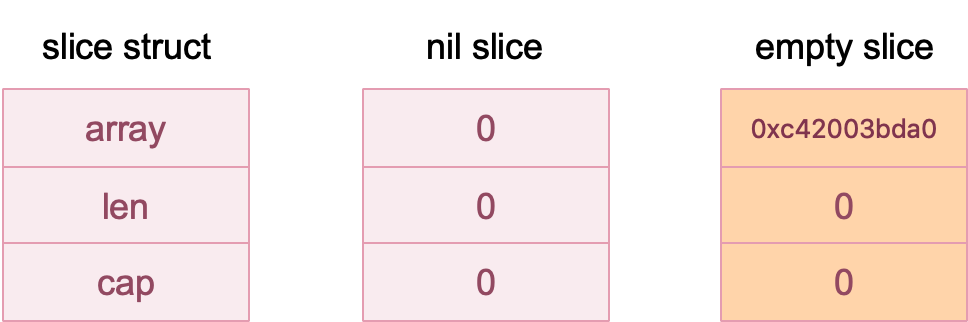
直接声明创建出来的 slice 其实是一个 nil slice。它的长度和容量都为0。和nil比较的结果为true。
这里比较混淆的是empty slice,它的长度和容量也都为0,但是所有的空切片的数据指针都指向同一个地址 0xc42003bda0。空切片和 nil 比较的结果为false。
它们的内部结构如下图:
| 创建方式 |
nil切片 |
空切片 |
| 方式一 |
var s1 []int |
var s2 = []int{} |
| 方式二 |
var s4 = *new([]int) |
var s3 = make([]int, 0) |
| 长度 |
0 |
0 |
| 容量 |
0 |
0 |
| 和 nil 比较 |
true |
false |
nil 切片和空切片很相似,长度和容量都是0,官方建议尽量使用 nil 切片。
初始化
Go 语言中包含三种初始化切片的方式:
- 通过下标的方式获得数组或者切片的一部分;
- 使用字面量初始化新的切片;
- 使用关键字 make 创建切片:
1
2
3
|
arr[0:3] or slice[0:3]
slice := []int{1, 2, 3}
slice := make([]int, 10)
|
使用下标
截取也是比较常见的一种创建 slice 的方法,可以从数组或者 slice 直接截取,当然需要指定起止索引位置。
截取操作采用如下方式:
1
2
|
data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
slice := data[2:4:6] // data[low, high, max]
|
对 data 使用3个索引值,截取出新的 slice。这里 data 可以是数组或者 slice。low 是最低索引值,这里是闭区间,也就是说第一个元素是 data 位于 low 索引处的元素;而 high 和 max 则是开区间,表示最后一个元素只能是索引 high-1 处的元素,而最大容量则只能是索引 max-1 处的元素。
当 high == low 时,新 slice 为空。
还有一点,high 和 max 必须在老数组或者老 slice 的容量(cap)范围内。
使用下标创建切片是最原始也最接近汇编语言的方式,它是所有方法中最为底层的一种,编译器会将 arr[0:3] 或者 slice[0:3] 等语句转换成 OpSliceMake 操作,我们可以通过下面的代码来验证一下:
1
2
3
4
5
6
7
8
|
// ch03/op_slice_make.go
package opslicemake
func newSlice() []int {
arr := [3]int{1, 2, 3}
slice := arr[0:1]
return slice
}
|
通过 GOSSAFUNC 变量编译上述代码可以得到一系列 SSA 中间代码,其中 slice := arr[0:1] 语句在 “decompose builtin” 阶段对应的代码如下所示:
1
2
3
4
5
6
|
v27 (+5) = SliceMake <[]int> v11 v14 v17
name &arr[*[3]int]: v11
name slice.ptr[*int]: v11
name slice.len[int]: v14
name slice.cap[int]: v17
|
SliceMake 操作会接受四个参数创建新的切片,元素类型、数组指针、切片大小和容量,这也是我们在数据结构一节中提到的切片的几个字段 .
基于已有 slice 创建新 slice 对象,被称为 reslice。新 slice 和老 slice 共用底层数组,新老 slice 对底层数组的更改都会影响到彼此。基于数组创建的新 slice 对象也是同样的效果:对数组或 slice 元素作的更改都会影响到彼此。
值得注意的是,新老 slice 或者新 slice 老数组互相影响的前提是两者共用底层数组,如果因为执行 append 操作使得新 slice 底层数组扩容,移动到了新的位置,两者就不会相互影响了。所以,问题的关键在于两者是否会共用底层数组。
字面量
当我们使用字面量 []int{1, 2, 3} 创建新的切片时,cmd/compile/internal/gc.slicelit 函数会在编译期间将它展开成如下所示的代码片段:
1
2
3
4
5
6
7
|
var vstat [3]int
vstat[0] = 1
vstat[1] = 2
vstat[2] = 3
var vauto *[3]int = new([3]int)
*vauto = vstat
slice := vauto[:]
|
- 根据切片中的元素数量对底层数组的大小进行推断并创建一个数组;
- 将这些字面量元素存储到初始化的数组中;
- 创建一个同样指向
[3]int 类型的数组指针;
- 将静态存储区的数组 vstat 赋值给 vauto 指针所在的地址;
- 通过
[:] 操作获取一个底层使用 vauto 的切片;
第 5 步中的 [:] 就是使用下标创建切片的方法,从这一点我们也能看出 [:] 操作是创建切片最底层的一种方法。
make关键字
如果使用字面量的方式创建切片,大部分的工作都会在编译期间完成。但是当我们使用 make 关键字创建切片时,很多工作都需要运行时的参与.调用方必须向 make 函数传入切片的大小以及可选的容量,类型检查期间的 cmd/compile/internal/gc.typecheck1 函数会校验入参:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
func typecheck1(n *Node, top int) (res*Node) {
switch n.Op {
...
case OMAKE:
args := n.List.Slice()
i := 1
switch t.Etype {
case TSLICE:
if i >= len(args) {
yyerror("missing len argument to make(%v)", t)
return n
}
l = args[i]
i++
var r *Node
if i < len(args) {
r = args[i]
}
...
if Isconst(l, CTINT) && r != nil && Isconst(r, CTINT) && l.Val().U.(*Mpint).Cmp(r.Val().U.(*Mpint)) > 0 {
yyerror("len larger than cap in make(%v)", t)
return n
}
n.Left = l
n.Right = r
n.Op = OMAKESLICE
}
...
}
}
|
上述函数不仅会检查 len 是否传入,还会保证传入的容量 cap 一定大于或者等于 len。除了校验参数之外,当前函数会将 OMAKE 节点转换成 OMAKESLICE,中间代码生成的 cmd/compile/internal/gc.walkexpr 函数会依据下面两个条件转换 OMAKESLICE 类型的节点:
- 切片的大小和容量是否足够小;
- 切片是否发生了逃逸,最终在堆上初始化
当切片发生逃逸或者非常大时,运行时需要 runtime.makeslice 在堆上初始化切片,如果当前的切片不会发生逃逸并且切片非常小的时候,make([]int, 3, 4) 会被直接转换成如下所示的代码:
1
2
|
var arr [4]int
n := arr[:3]
|
上述代码会初始化数组并通过下标 [:3] 得到数组对应的切片,这两部分操作都会在编译阶段完成,编译器会在栈上或者静态存储区创建数组并将 [:3] 转换成上一节提到的 OpSliceMake 操作。
分析了主要由编译器处理的分支之后,我们回到用于创建切片的运行时函数 runtime.makeslice,这个函数的实现很简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
// maxAlloc is the maximum size of an allocation. On 64-bit,
// it's theoretically possible to allocate 1<<heapAddrBits bytes. On
// 32-bit, however, this is one less than 1<<32 because the
// number of bytes in the address space doesn't actually fit
// in a uintptr.
maxAlloc = (1 << heapAddrBits) - (1-_64bit)*1
// 该函数传入需要初始化的切片的类型,长度以及容量,返回的指针会通过调用方组建成一个完成的slice结构体
// et: slice类型元信息,slice长度,slice容量
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// 判断类型,和容量的乘积会不会超过可分配内存的大小,以及长度是否为0和容量是否小于长度
// 调用MulUintptr函数:获取创建该切片需要的内存,是否溢出(超过2^64)
// 2^64是64位机能够表示的最大内存地址
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
// 如果溢出 | 超过能够分配的最大内存(2^32 - 1) | 非法输入, 报错并返回
if overflow || mem > maxAlloc || len < 0 || len > cap {
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// 如果都正常,则调用此函数申请返回一个连续 切片中元素大小×切片容量 长度的内存空间的指针
// 调用mallocgc函数分配一块连续内存并返回该内存的首地址
return mallocgc(mem, et, true)
}
// MulUintptr returns a * b and whether the multiplication overflowed.
// On supported platforms this is an intrinsic lowered by the compiler.
// MulUintptr利用一些已有常量计算所需内存大小并判断是否溢出。
func MulUintptr(a, b uintptr) (uintptr, bool) {
// 如果slice类型大小为0(如struct{}类型) 或 (a | b) < 2 ^ 32,肯定不会发生溢出
if a|b < 1<<(4*sys.PtrSize) || a == 0 {
return a * b, false
}
// 如果a * b > 2 ^64,说明发生了溢出
overflow := b > MaxUintptr/a
return a * b, overflow
}
|
上述函数的主要工作是计算切片占用的内存空间并在堆上申请一片连续的内存,它使用如下的方式计算占用的内存:
虽然编译期间可以检查出很多错误,但是在创建切片的过程中如果发生了以下错误会直接触发运行时错误并崩溃:
- 内存空间的大小发生了溢出;
- 申请的内存大于最大可分配的内存;
- 传入的长度小于 0 或者长度大于容量;
runtime.makeslice 在最后调用的 runtime.mallocgc 是用于申请内存的函数,这个函数的实现还是比较复杂,如果遇到了比较小的对象会直接初始化在 Go 语言调度器里面的 P 结构中,而大于 32KB 的对象会在堆上初始化.
在之前版本的 Go 语言中,数组指针、长度和容量会被合成一个 runtime.slice 结构,但是从 cmd/compile: move slice construction to callers of makeslice 提交之后,构建结构体 reflect.SliceHeader 的工作就都交给了 runtime.makeslice 的调用方,该函数仅会返回指向底层数组的指针,调用方会在编译期间构建切片结构体:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func typecheck1(n *Node, top int) (res*Node) {
switch n.Op {
...
case OSLICEHEADER:
switch
t := n.Type
n.Left = typecheck(n.Left, ctxExpr)
l := typecheck(n.List.First(), ctxExpr)
c := typecheck(n.List.Second(), ctxExpr)
l = defaultlit(l, types.Types[TINT])
c = defaultlit(c, types.Types[TINT])
n.List.SetFirst(l)
n.List.SetSecond(c)
...
}
}
|
OSLICEHEADER 操作会创建我们在上面介绍过的结构体 reflect.SliceHeader,其中包含数组指针、切片长度和容量,它是切片在运行时的表示:
1
2
3
4
5
|
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
|
正是因为大多数对切片类型的操作并不需要直接操作原来的 runtime.slice 结构体,所以 reflect.SliceHeader 的引入能够减少切片初始化时的少量开销,该改动不仅能够减少 0.2% 的 Go 语言包大小,还能够减少 92 个 runtime.panicIndex 的调用,占 Go 语言二进制的 3.5%。
访问元素
使用 len 和 cap 获取长度或者容量是切片最常见的操作,编译器将这它们看成两种特殊操作,即 OLEN 和 OCAP,cmd/compile/internal/gc.state.expr 函数会在 SSA 生成阶段阶段将它们分别转换成 OpSliceLen 和 OpSliceCap:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func (s *state) expr(n*Node) *ssa.Value {
switch n.Op {
case OLEN, OCAP:
switch {
case n.Left.Type.IsSlice():
op := ssa.OpSliceLen
if n.Op == OCAP {
op = ssa.OpSliceCap
}
return s.newValue1(op, types.Types[TINT], s.expr(n.Left))
...
}
...
}
}
|
访问切片中的字段可能会触发 “decompose builtin” 阶段的优化,len(slice) 或者 cap(slice) 在一些情况下会直接替换成切片的长度或者容量,不需要在运行时获取:
1
2
3
|
(SlicePtr (SliceMake ptr __)) -> ptr
(SliceLen (SliceMake _len_)) -> len
(SliceCap (SliceMake__ cap)) -> cap
|
除了获取切片的长度和容量之外,访问切片中元素使用的 OINDEX 操作也会在中间代码生成期间转换成对地址的直接访问:
1
2
3
4
5
6
7
8
9
10
11
12
|
func (s *state) expr(n*Node) *ssa.Value {
switch n.Op {
case OINDEX:
switch {
case n.Left.Type.IsSlice():
p := s.addr(n, false)
return s.load(n.Left.Type.Elem(), p)
...
}
...
}
}
|
切片的操作基本都是在编译期间完成的,除了访问切片的长度、容量或者其中的元素之外,编译期间也会将包含 range 关键字的遍历转换成形式更简单的循环,我们会在后面的章节中介绍使用 range 遍历切片的过程。
追加和扩容
使用 append 关键字向切片中追加元素也是常见的切片操作,中间代码生成阶段的 cmd/compile/internal/gc.state.append 方法会根据返回值是否会覆盖原变量,选择进入两种流程,如果 append 返回的新切片不需要赋值回原有的变量,就会进入如下的处理流程:
1
2
3
4
5
6
7
8
9
10
11
|
// append(slice, 1, 2, 3)
ptr, len, cap := slice
newlen := len + 3
if newlen > cap {
ptr, len, cap = growslice(slice, newlen)
newlen = len + 3
}
*(ptr+len) = 1
*(ptr+len+1) = 2
*(ptr+len+2) = 3
return makeslice(ptr, newlen, cap)
|
我们会先解构切片结构体获取它的数组指针、大小和容量,如果在追加元素后切片的大小大于容量,那么就会调用 runtime.growslice 对切片进行扩容并将新的元素依次加入切片。
如果使用 slice = append(slice, 1, 2, 3) 语句,那么 append 后的切片会覆盖原切片,这时 cmd/compile/internal/gc.state.append 方法会使用另一种方式展开关键字:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// slice = append(slice, 1, 2, 3)
a := &slice
ptr, len, cap := slice
newlen := len + 3
if uint(newlen) > uint(cap) {
newptr, len, newcap = growslice(slice, newlen)
vardef(a)
*a.cap = newcap
*a.ptr = newptr
}
newlen = len + 3
*a.len = newlen
*(ptr+len) = 1
*(ptr+len+1) = 2
*(ptr+len+2) = 3
|
是否覆盖原变量的逻辑其实差不多,最大的区别在于得到的新切片是否会赋值回原变量。如果我们选择覆盖原有的变量,就不需要担心切片发生拷贝影响性能,因为 Go 语言编译器已经对这种常见的情况做出了优化。
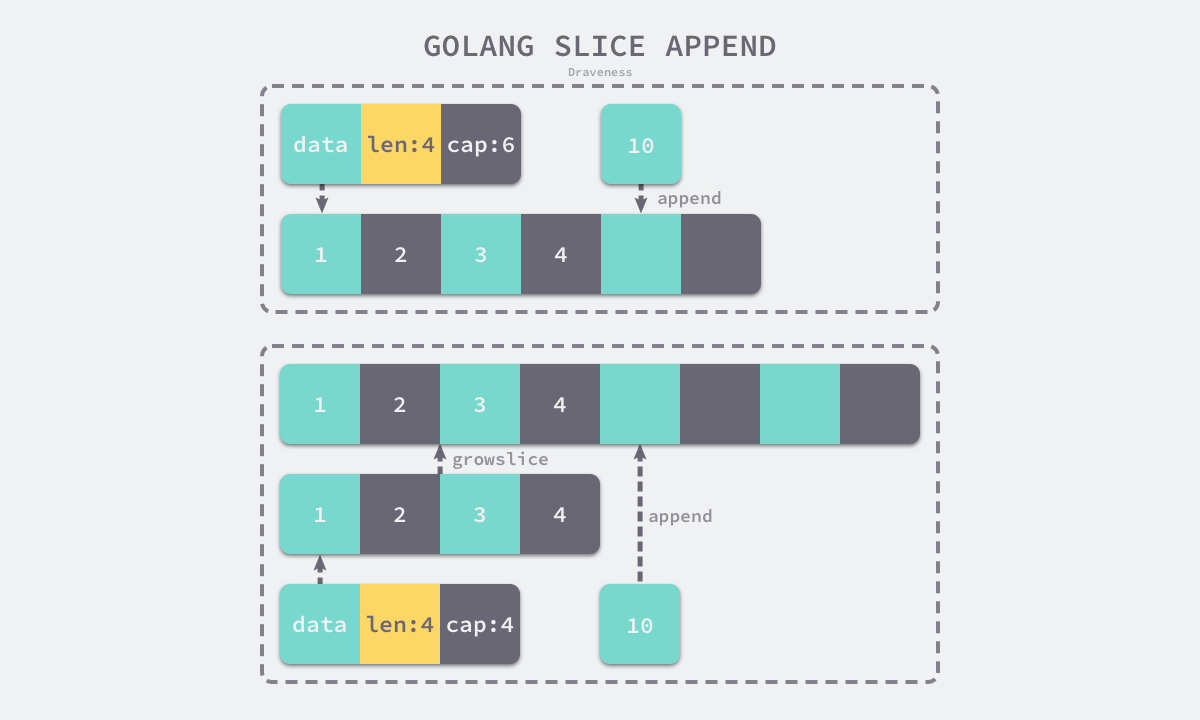
到这里我们已经清楚了 Go 语言如何在切片容量足够时向切片中追加元素,不过仍然需要研究切片容量不足时的处理流程。当切片的容量不足时,我们会调用 runtime.growslice 函数为切片扩容,扩容是为切片分配新的内存空间并拷贝原切片中元素的过程,我们先来看新切片的容量是如何确定的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
|
// growslice handles slice growth during append.
// It is passed the slice element type, the old slice, and the desired new minimum capacity,
// and it returns a new slice with at least that capacity, with the old data
// copied into it.
// The new slice's length is set to the old slice's length,
// NOT to the new requested capacity.
// This is for codegen convenience. The old slice's length is used immediately
// to calculate where to write new values during an append.
// TODO: When the old backend is gone, reconsider this decision.
// The SSA backend might prefer the new length or to return only ptr/cap and save stack space.
// 这个函数的参数依次是 元素的类型,老的 slice,新 slice 最小求的容量。
func growslice(et *_type, old slice, cap int) slice {
// 默认为false, 如果go build 时添加了 -race参数, raceenabled = true
if raceenabled {
callerpc := getcallerpc()
racereadrangepc(old.array, uintptr(old.len*int(et.size)), callerpc, funcPC(growslice))
}
// 默认为false, 如果go build 时添加了 -msan参数, msanenabled = true
if msanenabled {
msanread(old.array, uintptr(old.len*int(et.size)))
}
// 如果cap < old.cap,说明cap溢出
// 如果需求的容量小于就容量则报错
// 理论上来讲不应该出现这个问题
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
// append 没法创建一个nil指针的但是len不为0的切片
// 如果et.size, 说明类型大小为0, 直接返回 zerobase 类型的新切片
if et.size == 0 {
// append should not create a slice with nil pointer but non-zero len.
// We assume that append doesn't need to preserve old.array in this case.
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
newcap := old.cap
doublecap := newcap + newcap
// 如果需求容量大于双倍的旧容量那就直接使用需求容量
// 如果需要的容量大于老容量的2倍, 直接将扩容后新容量设置为需要的容量大小
// 也就是不需要进行2倍或者1.25倍的增长
if cap > doublecap {
newcap = cap
} else {
// 如果当前len小于1024则容量直接翻倍,否则按照1.25倍去递增直到满足需求容量
// 如果老容量小于1024, 2倍扩容
if old.cap < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
// 以1.25倍增大新容量, 直到溢出或者新容量大于需要的容量为止
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
// 如果溢出,那么将新容量设置为需要的容量
if newcap <= 0 {
newcap = cap
}
}
}
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.size.
// For 1 we don't need any division/multiplication.
// For sys.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
// 根据切片中的元素大小对齐内存,当数组中元素所占的字节大小为 1、8 或者 2 的倍数时,运行时会使用如下所示的代码对齐内存:
// 在扩容时不能单单按照len来判断扩容所需要的内存长度
// 还要根据切片的元素类型去进行内存对齐
// 当元素的占用字节数为1,8 或者2的倍数时会进行内存对对齐
// 内存对齐策略按照向上取整方式进行
// 取整的目标时go内存分配策略中67个class分页中的大小进行取整
switch {
// 当类型大小为1时,不需要乘除计算就能够得到所需要的值
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
// 内存对齐
capmem = roundupsize(uintptr(newcap))
// 判断是否溢出
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
// 当类型大小是8个字节时
case et.size == sys.PtrSize:
lenmem = uintptr(old.len) * sys.PtrSize
newlenmem = uintptr(cap) * sys.PtrSize
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
overflow = uintptr(newcap) > maxAlloc/sys.PtrSize
newcap = int(capmem / sys.PtrSize)
// 当类型大小是2的幂次方时
case isPowerOfTwo(et.size):
var shift uintptr
if sys.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
// 当大小不是上面任何一种时
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
// 在默认情况下,我们会将目标容量和元素大小相乘得到占用的内存。如果计算新容量时发生了内存溢出或者请求内存超过上限,就会直接崩溃退出程序
// The check of overflow in addition to capmem > maxAlloc is needed
// to prevent an overflow which can be used to trigger a segfault
// on 32bit architectures with this example program:
//
// type T [1<<27 + 1]int64
//
// var d T
// var s []T
//
// func main() {
// s = append(s, d, d, d, d)
// print(len(s), "\n")
// }
// 如果所需要的内存超过了最大可分配内存则panic
// 如果发生了溢出
if overflow || capmem > maxAlloc {
panic(errorString("growslice: cap out of range"))
}
var p unsafe.Pointer
// 如果当前元素类型不是指针,则会将超出切片当前长度的位置清空
// 并在最后使用 将原数组内存中的内容拷贝到新申请的内存中。
// 如果是切片类型是指针类型,那么会调用memclrNoHeapPointers将
// newlenmem以后的capmem-newlenmem全部置0
if et.ptrdata == 0 {
// 申请一块capmem大小的连续内存并返回首地址
p = mallocgc(capmem, nil, false)
// The append() that calls growslice is going to overwrite from old.len to cap (which will be the new length).
// Only clear the part that will not be overwritten.
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
// Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory.
// 如果是指针会根据进行gc方面对其进行加以保护以免空指针在分配期间被gc回收
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
// Only shade the pointers in old.array since we know the destination slice p
// only contains nil pointers because it has been cleared during alloc.
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem-et.size+et.ptrdata)
}
}
// 将老切片上的元素移动到新的内存中
memmove(p, old.array, lenmem)
//该函数最终会返回一个新的切片
// 返回新的切片
return slice{p, old.len, newcap}
}
|
如果切片类型大小为0,直接返回新切片.
在分配内存空间之前需要先确定新的切片容量,运行时根据切片的当前容量选择不同的策略进行扩容:
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果期望容量小于当前容量的两倍:
- 如果当前切片的长度小于 1024 就会将容量翻倍,直到新容量大于期望容量;
- 如果当前切片的长度大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;
扩容时除了上述策略,还有一个内存对齐,这个和内存分配策略相关。进行内存对齐之后,新 slice 的容量是要 大于等于 老 slice 容量的 2倍或者1.25倍。
我们来看一个例子。
1
2
3
4
5
6
7
8
9
|
package main
import "fmt"
func main() {
s := []int{1,2}
s = append(s,4,5,6)
fmt.Printf("len=%d, cap=%d",len(s),cap(s))
}
|
运行结果是:
例子中 s 原来只有 2 个元素,len 和 cap 都为 2,append 了三个元素后,长度变为 5,容量最小要变成 5,即调用 growslice 函数时,传入的第三个参数应该为 5。即 cap=5。而一方面,doublecap 是原 slice容量的 2 倍,等于 4。满足第一个 if 条件,所以 newcap 变成了 5。
接着调用了 roundupsize 函数,传入 40。(代码中ptrSize是指一个指针的大小,在64位机上是8)
我们再看内存对齐,搬出 roundupsize 函数的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
const _MaxSmallSize = 32768
const smallSizeMax = 1024
const smallSizeDiv = 8
// 这是 Go 源码中有关内存分配的两个 slice。class_to_size通过 spanClass获取 span划分的 object大小。而 size_to_class8 表示通过 size 获取它的 spanClass。
var size_to_class8 = [smallSizeMax/smallSizeDiv + 1]uint8{0, 1, 2, 3, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10, 11, 11, 12, 12, 13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 19, 19, 19, 19, 20, 20, 20, 20, 21, 21, 21, 21, 22, 22, 22, 22, 23, 23, 23, 23, 24, 24, 24, 24, 25, 25, 25, 25, 26, 26, 26, 26, 27, 27, 27, 27, 27, 27, 27, 27, 28, 28, 28, 28, 28, 28, 28, 28, 29, 29, 29, 29, 29, 29, 29, 29, 30, 30, 30, 30, 30, 30, 30, 30, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32}
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 24, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
// Returns size of the memory block that mallocgc will allocate if you ask for the size.
// 函数会将待申请的内存向上取整,取整时会使用 `runtime.class_to_size` 数组,使用该数组中的整数可以提高内存的分配效率并减少碎片:
func roundupsize(size uintptr) uintptr {
if size < _MaxSmallSize {
if size <= smallSizeMax-8 {
return uintptr(class_to_size[size_to_class8[divRoundUp(size, smallSizeDiv)]])
} else {
return uintptr(class_to_size[size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]])
}
}
if size+_PageSize < size {
return size
}
return alignUp(size, _PageSize)
}
// alignUp rounds n up to a multiple of a. a must be a power of 2.
func alignUp(n, a uintptr) uintptr {
return (n + a - 1) &^ (a - 1)
}
// divRoundUp returns ceil(n / a).
func divRoundUp(n, a uintptr) uintptr {
// a is generally a power of two. This will get inlined and
// the compiler will optimize the division.
return (n + a - 1) / a
}
|
很明显,我们最终将返回这个式子的结果:
1
|
class_to_size[size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]]
|
我们传进去的 size 等于 40。所以 (size+smallSizeDiv-1)/smallSizeDiv = 5;获取 size_to_class8 数组中索引为 5 的元素为 4;获取 class_to_size 中索引为 4 的元素为 48。
最终,新的 slice 的容量为 6:
1
|
newcap = int(capmem / ptrSize) // 6
|
如果切片中元素不是指针类型,那么会调用 runtime.memclrNoHeapPointers 将超出切片当前长度的位置清空并在最后使用 runtime.memmove 将原数组内存中的内容拷贝到新申请的内存中。这两个方法都是用目标机器上的汇编指令实现的,这里就不展开介绍了。
runtime.growslice 函数最终会返回一个新的切片,其中包含了新的数组指针、大小和容量,这个返回的三元组最终会覆盖原切片。
深拷贝切片
对slice进行的截取,新的slice和原始slice共用同一个底层数组,因此可以看做是对slice的浅拷贝,那么在go中如何实现对slice的深拷贝呢?那么就要依赖golang提供的copy函数了.
切片的拷贝虽然不是常见的操作,但是却是我们学习切片实现原理必须要涉及的。当我们使用 copy(a, b) 的形式对切片进行拷贝时,编译期间的 cmd/compile/internal/gc.copyany 也会分两种情况进行处理拷贝操作,如果当前 copy 不是在运行时调用的,copy(a, b) 会被直接转换成下面的代码:
1
2
3
4
5
6
7
|
n := len(a)
if n > len(b) {
n = len(b)
}
if a.ptr != b.ptr {
memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
}
|
我们来看下面代码
1
2
3
4
5
6
7
8
9
10
11
12
|
package main
import "fmt"
func main() {
aSlice := []int{1, 2, 3}
bSlice := []int{4, 5, 6, 7, 8, 9}
copy(bSlice, aSlice)
fmt.Println(aSlice, bSlice)//[1 2 3] [1 2 3 7 8 9]
//如果是 copy( aSlice, bSlice) 则结果是 [4 5 6]
}
|
也就是说 copy() 函数有两个参数,一个是 to 一个是 from,就是将第二个 copy 到第一个上面,如果第一个长度小于第二个,那么就会 copy 与第一个等长度的值,如 copy( aSlice, bSlice) 的结果是 [4 5 6] ,反之则是短的覆盖长的前几位。当然我们也可以指定复制长度
1
2
3
4
5
6
7
8
9
10
11
|
package main
import "fmt"
func main() {
aSlice := []int{1, 2, 3}
bSlice := []int{4, 5, 6, 7, 8, 9}
copy(bSlice[2:5], aSlice)
fmt.Println(aSlice, bSlice)//[1 2 3] [4 5 1 2 3 9]
}
|
runtime.memmove 会负责拷贝内存。而如果拷贝是在运行时发生的,例如:go copy(a, b),编译器会使用 runtime.slicecopy 替换运行期间调用的 copy,该函数的实现很简单:
关于 slice 的 copy 的规则逻辑我们也可以在源码中看出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
func slicecopy(to, fm slice, width uintptr) int {
// 如果源切片或者目标切片有一个长度为0,那么就不需要拷贝,直接 return
if fm.len == 0 || to.len == 0 {
return 0
}
// n 记录下源切片或者目标切片较短的那一个的长度
n := fm.len
if to.len < n {
n = to.len
}
// 如果入参 width = 0,也不需要拷贝了,返回较短的切片的长度
if width == 0 {
return n
}
// 如果开启了竞争检测
if raceenabled {
callerpc := getcallerpc(unsafe.Pointer(&to))
pc := funcPC(slicecopy)
racewriterangepc(to.array, uintptr(n*int(width)), callerpc, pc)
racereadrangepc(fm.array, uintptr(n*int(width)), callerpc, pc)
}
// 如果开启了 The memory sanitizer (msan)
if msanenabled {
msanwrite(to.array, uintptr(n*int(width)))
msanread(fm.array, uintptr(n*int(width)))
}
size := uintptr(n) * width
if size == 1 {
// TODO: is this still worth it with new memmove impl?
// 如果只有一个元素,那么指针直接转换即可
*(*byte)(to.array) = *(*byte)(fm.array) // known to be a byte pointer
} else {
// 如果不止一个元素,那么就把 size 个 bytes 从 fm.array 地址开始,拷贝到 to.array 地址之后
memmove(to.array, fm.array, size)
}
return n
}
|
无论是编译期间拷贝还是运行时拷贝,两种拷贝方式都会通过 runtime.memmove 将整块内存的内容拷贝到目标的内存区域中:
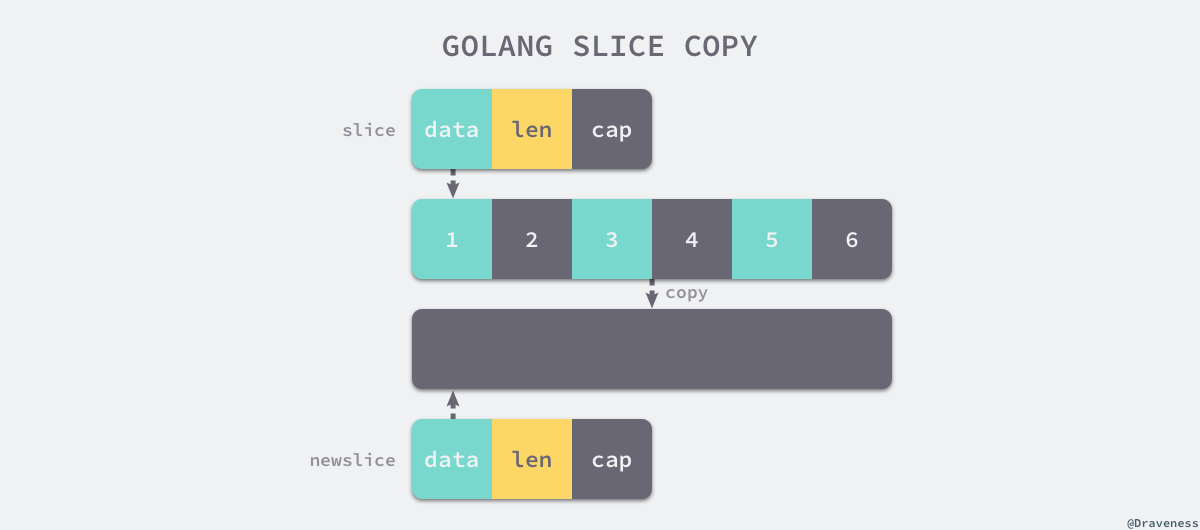
相比于依次拷贝元素,runtime.memmove 能够提供更好的性能。需要注意的是,整块拷贝内存仍然会占用非常多的资源,在大切片上执行拷贝操作时一定要注意对性能的影响。
小结
切片的很多功能都是由运行时实现的,无论是初始化切片,还是对切片进行追加或扩容都需要运行时的支持,需要注意的是在遇到大切片扩容或者复制时可能会发生大规模的内存拷贝,一定要减少类似操作避免影响程序的性能。
string
字符串是 Go 语言中的基础数据类型,虽然字符串往往被看做一个整体,但是它实际上是一片连续的内存空间,我们也可以将它理解成一个由字符组成的数组,本节会详细介绍字符串的实现原理、转换过程以及常见操作的实现。
字符串是由字符组成的数组,C 语言中的字符串使用字符数组 char[] 表示。数组会占用一片连续的内存空间,而内存空间存储的字节共同组成了字符串,Go 语言中的字符串只是一个只读的字节数组,下图展示了 “hello” 字符串在内存中的存储方式:

如果是代码中存在的字符串,编译器会将其标记成只读数据 SRODATA,假设我们有以下代码,其中包含了一个字符串,当我们将这段代码编译成汇编语言时,就能够看到 hello 字符串有一个 SRODATA 的标记:
1
2
3
4
5
6
7
|
$ cat main.go
package main
func main() {
str := "hello"
println([]byte(str))
}
|
1
2
3
4
5
|
$ GOOS=linux GOARCH=amd64 go tool compile -S main.go
...
go.string."hello" SRODATA dupok size=5
0x0000 68 65 6c 6c 6f hello
...
|
只读只意味着字符串会分配到只读的内存空间,但是 Go 语言只是不支持直接修改 string 类型变量的内存空间,我们仍然可以通过在 string 和 []byte 类型之间反复转换实现修改这一目的:
- 先将这段内存拷贝到堆或者栈上;
- 将变量的类型转换成 []byte 后并修改字节数据;
- 将修改后的字节数组转换回 string;
Java、Python 以及很多编程语言的字符串也都是不可变的,这种不可变的特性可以保证我们不会引用到意外发生改变的值,而因为 Go 语言的字符串可以作为哈希的键,所以如果哈希的键是可变的,不仅会增加哈希实现的复杂度,还可能会影响哈希的比较。
数据结构
字符串在 Go 语言中的接口其实非常简单,每一个字符串在运行时都会使用如下的 reflect.StringHeader 表示,其中包含指向字节数组的指针和数组的大小:
1
2
3
4
|
type StringHeader struct {
Data uintptr
Len int
}
|
与切片的结构体相比,字符串只少了一个表示容量的 Cap 字段,而正是因为切片在 Go 语言的运行时表示与字符串高度相似,所以我们经常会说字符串是一个只读的切片类型。
1
2
3
4
5
|
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
|
因为字符串作为只读的类型,我们并不会直接向字符串直接追加元素改变其本身的内存空间,所有在字符串上的写入操作都是通过拷贝实现的。
字符串的值是不能改变的,这句话其实不完整,应该说字符串的值不能被更改,但可以被替换。 还是以string的结构体来解释吧,所有的string在底层都是这样的一个结构体stringStruct{str: str_point, len: str_len},string结构体的str指针指向的是一个字符常量的地址, 这个地址里面的内容是不可以被改变的,因为它是只读的,但是这个指针可以指向不同的地址,我们来对比一下string、[]byte类型重新赋值的区别:
1
2
|
s := "A1" // 分配存储"A1"的内存空间,s结构体里的str指针指向这快内存
s = "A2" // 重新给"A2"的分配内存空间,s结构体里的str指针指向这快内存
|
其实[]byte和string的差别是更改变量的时候array的内容可以被更改。
1
2
|
s := []byte{1} // 分配存储1数组的内存空间,s结构体的array指针指向这个数组。
s = []byte{2} // 将array的内容改为2
|
因为string的指针指向的内容是不可以更改的,所以每更改一次字符串,就得重新分配一次内存,之前分配空间的还得由gc回收,这是导致string操作低效的根本原因。
解析过程
解析器会在词法分析阶段解析字符串,词法分析阶段会对源文件中的字符串进行切片和分组,将原有无意义的字符流转换成 Token 序列。我们可以使用两种字面量方式在 Go 语言中声明字符串,即双引号和反引号:
1
2
3
|
str1 := "this is a string"
str2 := `this is another
string`
|
使用双引号声明的字符串和其他语言中的字符串没有太多的区别,它只能用于单行字符串的初始化,如果字符串内部出现双引号,需要使用 \ 符号避免编译器的解析错误,而反引号声明的字符串可以摆脱单行的限制。当使用反引号时,因为双引号不再负责标记字符串的开始和结束,我们可以在字符串内部直接使用 “,在遇到需要手写 JSON 或者其他复杂数据格式的场景下非常方便。
1
|
json := `{"author": "draven", "tags": ["golang"]}`
|
两种不同的声明方式其实也意味着 Go 语言编译器需要能够区分并且正确解析两种不同的字符串格式。解析字符串使用的扫描器 cmd/compile/internal/syntax.scanner 会将输入的字符串转换成 Token 流,cmd/compile/internal/syntax.scanner.stdString 方法是它用来解析使用双引号的标准字符串:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func (s *scanner) stdString() {
s.startLit()
for {
r := s.getr()
if r == '"' {
break
}
if r == '\\' {
s.escape('"')
continue
}
if r == '\n' {
s.ungetr()
s.error("newline in string")
break
}
if r < 0 {
s.errh(s.line, s.col, "string not terminated")
break
}
}
s.nlsemi = true
s.lit = string(s.stopLit())
s.kind = StringLit
s.tok = _Literal
}
|
从这个方法的实现我们能分析出 Go 语言处理标准字符串的逻辑:
- 标准字符串使用双引号表示开头和结尾;
- 标准字符串需要使用反斜杠 \ 来逃逸双引号;
- 标准字符串不能出现如下所示的隐式换行 \n;
使用反引号声明的原始字符串的解析规则就非常简单了,cmd/compile/internal/syntax.scanner.rawString 会将非反引号的所有字符都划分到当前字符串的范围中,所以我们可以使用它支持复杂的多行字符串:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func (s *scanner) rawString() {
s.startLit()
for {
r := s.getr()
if r == '`' {
break
}
if r < 0 {
s.errh(s.line, s.col, "string not terminated")
break
}
}
s.nlsemi = true
s.lit = string(s.stopLit())
s.kind = StringLit
s.tok = _Literal
}
|
无论是标准字符串还是原始字符串都会被标记成 StringLit 并传递到语法分析阶段。在语法分析阶段,与字符串相关的表达式都会由 cmd/compile/internal/gc.noder.basicLit 方法处理:
1
2
3
4
5
6
7
8
9
10
|
func (p *noder) basicLit(lit*syntax.BasicLit) Val {
switch s := lit.Value; lit.Kind {
case syntax.StringLit:
if len(s) > 0 && s[0] == '`' {
s = strings.Replace(s, "\r", "", -1)
}
u, _ := strconv.Unquote(s)
return Val{U: u}
}
}
|
无论是 import 语句中包的路径、结构体中的字段标签还是表达式中的字符串都会使用这个方法将原生字符串中最后的换行符删除并对字符串 Token 进行 Unquote,也就是去掉字符串两边的引号等无关干扰,还原其本来的面目。
strconv.Unquote 处理了很多边界条件导致实现非常复杂,其中不仅包括引号,还包括 UTF-8 等编码的处理逻辑,这里也就不展开介绍了。
底层存储
1
2
3
4
5
6
7
8
9
10
11
12
|
s1 := "hello world"
s2 := "hello world"
s3 := "hello world"
fmt.Println(&s1,&s2,&s3)
fmt.Println((*reflect.StringHeader)(unsafe.Pointer(&s1)),
(*reflect.StringHeader)(unsafe.Pointer(&s2)),
(*reflect.StringHeader)(unsafe.Pointer(&s3)))
/*
0xc000010200 0xc000010210 0xc000010220
&{17633267 11} &{17633267 11} &{17633267 11}
*/
|
可以看出来,如果string是由字面量赋值的话,string在底层的data段都是一个地址,不同的字符串变量指向相同的底层数组,这是因为字符串是只读的,为了节省内存,相同字面量的字符串通常对应于同一字符串常量。
1
2
3
4
5
6
7
8
9
|
package main
func main() {
s1 := "aaa"
s2 := "bbb" + "ccc"
s3 := "aaa" + "bbb"
s4 := "ddd"
_, _, _,_ = s1, s2, s3,s4
}
|
1
2
3
4
5
6
7
8
9
|
go tool compile -S -B -N -l main.go
go.string."aaa" SRODATA dupok size=3
0x0000 61 61 61 aaa
go.string."bbbccc" SRODATA dupok size=6
0x0000 62 62 62 63 63 63 bbbccc
go.string."aaabbb" SRODATA dupok size=6
0x0000 61 61 61 62 62 62 aaabbb
go.string."ddd" SRODATA dupok size=3
0x0000 64 64 64 ddd
|
可以看到,代码中的”aaa”+”bbb”会被编译器合并为一个”aaabbb”常量字符串。
拼接
Go 语言拼接字符串会使用 + 符号,编译器会将该符号对应的 OADD 节点转换成 OADDSTR 类型的节点,随后在 cmd/compile/internal/gc.walkexpr 中调用 cmd/compile/internal/gc.addstr 函数生成用于拼接字符串的代码:
1
2
3
4
5
6
7
|
func walkexpr(n *Node, init*Nodes) *Node {
switch n.Op {
...
case OADDSTR:
n = addstr(n, init)
}
}
|
cmd/compile/internal/gc.addstr 能帮助我们在编译期间选择合适的函数对字符串进行拼接,该函数会根据带拼接的字符串数量选择不同的逻辑:
- 如果小于或者等于 5 个,那么会调用
concatstring{2,3,4,5} 等一系列函数;
- 如果超过 5 个,那么会选择
runtime.concatstrings 传入一个数组切片;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
func addstr(n *Node, init*Nodes) *Node {
c := n.List.Len()
buf := nodnil()
args := []*Node{buf}
for _, n2 := range n.List.Slice() {
args = append(args, conv(n2, types.Types[TSTRING]))
}
var fn string
if c <= 5 {
fn = fmt.Sprintf("concatstring%d", c)
} else {
fn = "concatstrings"
t := types.NewSlice(types.Types[TSTRING])
slice := nod(OCOMPLIT, nil, typenod(t))
slice.List.Set(args[1:])
args = []*Node{buf, slice}
}
cat := syslook(fn)
r := nod(OCALL, cat, nil)
r.List.Set(args)
...
return r
}
|
其实无论使用 concatstring{2,3,4,5} 中的哪一个,最终都会调用 runtime.concatstrings,它会先对遍历传入的切片参数,再过滤空字符串并计算拼接后字符串的长度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0
count := 0
for i, x := range a {
n := len(x)
if n == 0 {
continue
}
l += n
count++
idx = i
}
if count == 0 {
return ""
}
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx]
}
s, b := rawstringtmp(buf, l)
for _, x := range a {
copy(b, x)
b = b[len(x):]
}
return s
}
|
如果非空字符串的数量为 1 并且当前的字符串不在栈上,就可以直接返回该字符串,不需要做出额外操作。
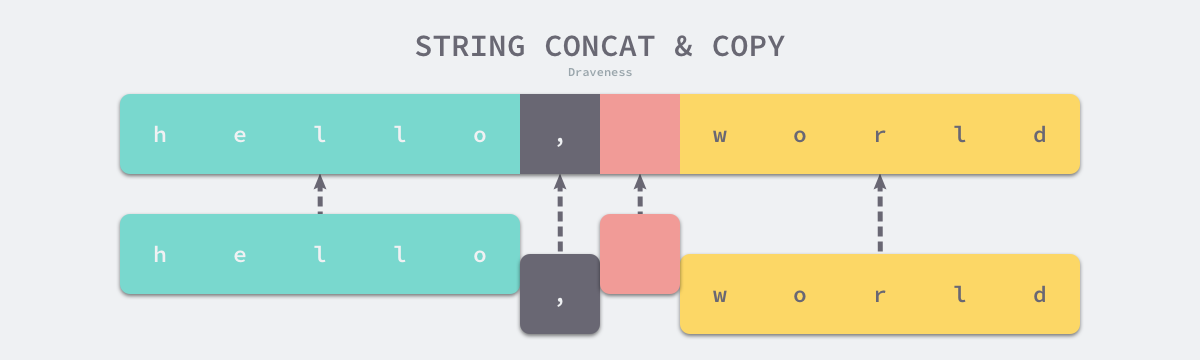
但是在正常情况下,运行时会调用 copy 将输入的多个字符串拷贝到目标字符串所在的内存空间。新的字符串是一片新的内存空间,与原来的字符串也没有任何关联,一旦需要拼接的字符串非常大,拷贝带来的性能损失是无法忽略的。
string与[]byte
string是一个8位字节的集合,通常但不一定代表UTF-8编码的文本。string可以为空,但是不能为nil。string的值是不能改变的。
1
2
3
4
|
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text. A string may be empty, but
// not nil. Values of string type are immutable.
type string string
|
在go的源码中src/runtime/string.go,string的定义如下:
1
2
3
4
|
type stringStruct struct {
str unsafe.Pointer
len int
}
|
可以看到str其实是个指针,指向某个数组的首地址,另一个字段是len长度。那到这个数组是什么呢?其实就是byte数组,而且要注意string其实就是个struct。
在go里面,byte是uint8的别名。
1
2
3
4
|
// byte is an alias for uint8 and is equivalent to uint8 in all ways. It is
// used, by convention, to distinguish byte values from 8-bit unsigned
// integer values.
type byte = uint8
|
我们可以看到byte就是uint8的别名,它是用来区分字节值和8位无符号整数值。
其实可以把byte当作一个ASCII码的一个字符。
1
2
3
|
var ch byte = 65
var ch byte = '\x41'
var ch byte = 'A'
|
slice结构在go的源码中src/runtime/slice.go定义:
1
2
3
4
5
|
type slice struct {
array unsafe.Pointer
len int
cap int
}
|
array是数组的指针,len表示长度,cap表示容量。除了cap,其他看起来和string的结构很像。
[]rune
golang内置类型有rune类型和byte类型。除开rune和byte底层的类型的区别,在使用上,rune能处理一切的字符,而byte仅仅局限在ascii.
需要知晓的是rune类型的底层类型是int32类型,而byte类型的底层类型是int8类型,这决定了rune能比byte表达更多的数。
在unicode中,一个中文占两个字节,utf-8中一个中文占三个字节,golang默认的编码是utf-8编码,因此默认一个中文占三个字节,但是golang中的字符串底层实际上是一个byte数组。因此可能会出现下面这种奇怪的情况
1
2
|
str := "hello 世界"
fmt.Println(len(str)) //12
|
我们期望得到的结果应该是8,原因是golang中的string底层是由一个byte数组实现的,而golang默认的编码是utf-8,因此在这里一个中文字符占3个字节,所以获得的长度是12,想要获得我们想要的结果也很简单,golang中的unicode/utf8包提供了用utf-8获取长度的方法
1
2
|
str := "hello 世界"
fmt.Println(utf8.RuneCountInString(str)) //8
|
上面说了byte类型实际上是一个int8类型,int8适合表达ascii编码的字符,而int32可以表达更多的数,可以更容易的处理unicode字符,因此,我们可以通过rune类型来处理unicode字符
1
2
3
|
str := "hello 世界"
str2 := []rune(str)
fmt.Println(len(str2)) //8
|
这里会将申请一块内存,然后将str的内容复制到这块内存,实际上这块内存是一个rune类型的切片,而str2拿到的是一个rune类型的切片的引用,我们可以很容易的证明这是一个引用
1
2
3
4
5
|
str := "hello 世界"
str2 := []rune(str)
t := str2
t[0] = 'w'
fmt.Println(string(str2)) //“wello 世界”
|
通过把str2赋值给t,t上改变的数据,实际上是改变的是t指向的rune切片,因此,str也会跟着改变
类型转换
当我们使用 Go 语言解析和序列化 JSON 等数据格式时,经常需要将数据在 string 和 []byte 之间来回转换,类型转换的开销并没有想象的那么小,我们经常会看到 runtime.slicebytetostring 等函数出现在火焰图中,成为程序的性能热点。
从字节数组到字符串的转换需要使用 runtime.slicebytetostring 函数,例如:string(bytes),该函数在函数体中会先处理两种比较常见的情况,也就是长度为 0 或者 1 的字节数组,这两种情况处理起来都非常简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
func slicebytetostring(buf *tmpBuf, b []byte) (str string) {
l := len(b)
if l == 0 {
return ""
}
if l == 1 {
stringStructOf(&str).str = unsafe.Pointer(&staticbytes[b[0]])
stringStructOf(&str).len = 1
return
}
var p unsafe.Pointer
if buf != nil && len(b) <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(len(b)), nil, false)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = len(b)
memmove(p, (*(*slice)(unsafe.Pointer(&b))).array, uintptr(len(b)))
return
}
|
处理过后会根据传入的缓冲区大小决定是否需要为新字符串分配一片内存空间,runtime.stringStructOf 会将传入的字符串指针转换成 runtime.stringStruct 结构体指针,然后设置结构体持有的字符串指针 str 和长度 len,最后通过 runtime.memmove 将原 []byte 中的字节全部复制到新的内存空间中。
当我们想要将字符串转换成 []byte 类型时,需要使用 runtime.stringtoslicebyte 函数,该函数的实现非常容易理解:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}
// rawbyteslice allocates a new byte slice. The byte slice is not zeroed.
func rawbyteslice(size int) (b []byte) {
cap := roundupsize(uintptr(size))
p := mallocgc(cap, nil, false)
if cap != uintptr(size) {
memclrNoHeapPointers(add(p, uintptr(size)), cap-uintptr(size))
}
*(*slice)(unsafe.Pointer(&b)) = slice{p, size, int(cap)}
return
}
|
上述函数会根据是否传入缓冲区做出不同的处理:
- 当传入缓冲区时,它会使用传入的缓冲区存储
[]byte;
- 当没有传入缓冲区时,运行时会调用
runtime.rawbyteslice 创建新的字节切片并将字符串中的内容拷贝过去;
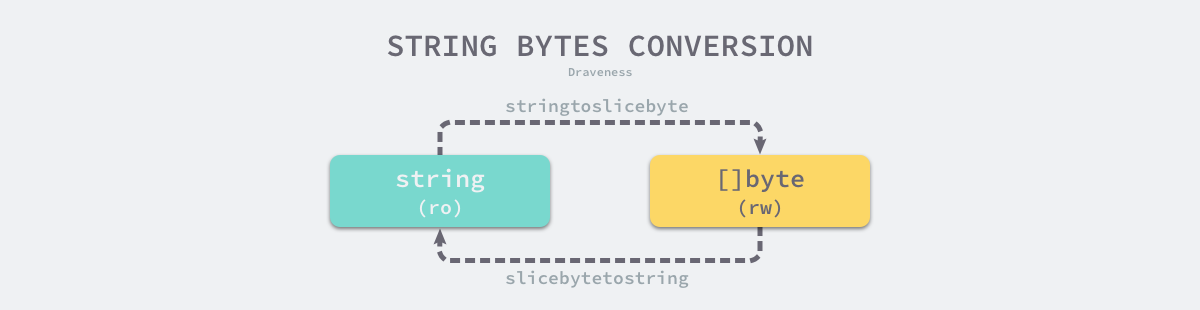
最后我们会通过调用copy方法实现string到[]byte的拷贝,具体实现在src/runtime/slice.go中的slicestringcopy方法,这段代码的核心思路就是:将string的底层数组从头部复制n个到[]byte对应的底层数组中去
字符串和 []byte 中的内容虽然一样,但是字符串的内容是只读的,我们不能通过下标或者其他形式改变其中的数据,而 []byte 中的内容是可以读写的。不过无论从哪种类型转换到另一种都需要拷贝数据,而内存拷贝的性能损耗会随着字符串和 []byte 长度的增长而增长。
无拷贝类型转换
标准的转换方法都会发生内存拷贝,所以为了减少内存拷贝和内存申请我们可以使用强转换的方式对两者进行转换:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func string2byte(s string) []byte {
sh := (*reflect.StringHeader)(unsafe.Pointer(&s))
bh := reflect.SliceHeader{
Data: sh.Data,
Len: sh.Len,
Cap: sh.Len,
}
return *(*[]byte)(unsafe.Pointer(&bh))
}
func byte2string(b []byte) string{
bh := (*reflect.SliceHeader)(unsafe.Pointer(&b))
sh := reflect.StringHeader{
Data: bh.Data,
Len: bh.Len,
}
return *(*string)(unsafe.Pointer(&sh))
}
|
通过unsafe.Pointer和reflect.XXXHeader取到了数据首地址,并实现了string和[]byte的直接转换(这些操作在语言层面是禁止的)。
这样的转化过程依赖于二者的数据结构:
1
2
3
4
5
6
7
8
9
10
|
struct string{
uint8 *str;
int len;
}
struct []uint8{
uint8 *array;
int len;
int cap;
}
|
如果你是在高性能场景下使用,是可以考虑使用强转换的方式的,但是要注意强转换的使用方式,他不是安全的,这里举个例子:
1
2
3
4
5
6
7
8
9
10
11
|
func stringtoslicebytetmp(s string) []byte {
str := (*reflect.StringHeader)(unsafe.Pointer(&s))
ret := reflect.SliceHeader{Data: str.Data, Len: str.Len, Cap: str.Len}
return *(*[]byte)(unsafe.Pointer(&ret))
}
func main() {
str := "hello"
by := stringtoslicebytetmp(str)
by[0] = 'H'
}
|
运行结果:
1
2
3
|
unexpected fault address 0x109d65f
fatal error: fault
[signal SIGBUS: bus error code=0x2 addr=0x109d65f pc=0x107eabc]
|
我们可以看到程序直接发生严重错误了,即使使用defer+recover也无法捕获。原因是什么呢?
我们前面介绍过,string类型是不能改变的,也就是底层数据是不能更改的,这里因为我们使用的是强转换的方式,那么by指向了str的底层数组,现在对这个数组中的元素进行更改,就会出现这个问题,导致整个程序down掉!
使用场景
既然string就是一系列字节,而[]byte也可以表达一系列字节,那么实际运用中应当如何取舍?
- string可以直接比较,而
[]byte不可以,所以[]byte不可以当map的key值。
- 因为无法修改string中的某个字符,需要粒度小到操作一个字符时,用
[]byte。
- string值不可为nil,所以如果你想要通过返回nil表达额外的含义,就用
[]byte。
[]byte切片这么灵活,想要用切片的特性就用[]byte。- 需要大量字符串处理的时候用
[]byte,性能好很多。
小结
字符串是 Go 语言中相对来说比较简单的一种数据结构,我们在这一节中详细分析了字符串与 []byte 类型的关系,从词法分析阶段理解字符串是如何被解析的,作为只读的数据类型,我们无法改变其本身的结构,但是在做拼接和类型转换等操作时一定要注意性能的损耗,遇到需要极致性能的场景一定要尽量减少类型转换的次数。
参考
3.1 数组
3.2 切片
3.4 字符串
深度解密Go语言之Slice
「Golang」Slice源码讲解
GoLang学习之slice源码剖析
面试官:你能聊聊string和[]byte的转换吗?