前言
当我们想要在 Go 语言中初始化一个结构时,可能会用到两个不同的关键字 — make 和 new。因为它们的功能相似,所以初学者可能会对这两个关键字的作用感到困惑,但是它们两者能够初始化的变量却有较大的不同。
- make 的作用是初始化内置的数据结构,也就是我们在前面提到的切片、哈希表和 Channel;
- new 的作用是根据传入的类型分配一片内存空间并返回指向这片内存空间的指针;
new(T) 返回的是 T 的指针
new(T) 为一个 T 类型新值分配空间并将此空间初始化为 T 的零值,返回的是新值的地址,也就是 T 类型的指针 *T,该指针指向 T 的新分配的零值。
1
2
3
4
5
6
7
8
|
p1 := new(int)
fmt.Printf("p1 --> %#v \n ", p1) //(*int)(0xc42000e250)
fmt.Printf("p1 point to --> %#v \n ", *p1) //0
var p2 *int
i := 0
p2 = &i
fmt.Printf("p2 --> %#v \n ", p2) //(*int)(0xc42000e278)
fmt.Printf("p2 point to --> %#v \n ", *p2) //0
|
上面的代码是等价的,new(int) 将分配的空间初始化为 int 的零值,也就是 0,并返回 int 的指针,这和直接声明指针并初始化的效果是相同的。
make 只能用于 slice,map,channel
make 只能用于 slice,map,channel 三种类型,make(T, args) 返回的是初始化之后的 T 类型的值,这个新值并不是 T 类型的零值,也不是指针 *T,是经过初始化之后的 T 的引用。因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。
1
2
3
4
5
6
7
8
9
10
|
var s1 []int
if s1 == nil {
fmt.Printf("s1 is nil --> %#v \n ", s1) // []int(nil)
}
s2 := make([]int, 3)
if s2 == nil {
fmt.Printf("s2 is nil --> %#v \n ", s2)
} else {
fmt.Printf("s2 is not nill --> %#v \n ", s2)// []int{0, 0, 0}
}
|
slice 的零值是 nil,使用 make 之后 slice 是一个初始化的 slice,即 slice 的长度、容量、底层指向的 array 都被 make 完成初始化,此时 slice 内容被类型 int 的零值填充,形式是 [0 0 0],map 和 channel 也是类似的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
var m1 map[int]string
if m1 == nil {
fmt.Printf("m1 is nil --> %#v \n ", m1) //map[int]string(nil)
}
m2 := make(map[int]string)
if m2 == nil {
fmt.Printf("m2 is nil --> %#v \n ", m2)
} else {
fmt.Printf("m2 is not nill --> %#v \n ", m2) map[int]string{}
}
var c1 chan string
if c1 == nil {
fmt.Printf("c1 is nil --> %#v \n ", c1) //(chan string)(nil)
}
c2 := make(chan string)
if c2 == nil {
fmt.Printf("c2 is nil --> %#v \n ", c2)
} else {
fmt.Printf("c2 is not nill --> %#v \n ", c2)//(chan string)(0xc420016120)
}
|
很少需要使用 new
以下代码演示了 struct 初始化的过程,可以说明不使用 new 一样可以完成 struct 的初始化工作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
type Foo struct {
name string
age int
}
//声明初始化
var foo1 Foo
fmt.Printf("foo1 --> %#v\n ", foo1) //main.Foo{age:0, name:""}
foo1.age = 1
fmt.Println(foo1.age)
//struct literal 初始化
foo2 := Foo{}
fmt.Printf("foo2 --> %#v\n ", foo2) //main.Foo{age:0, name:""}
foo2.age = 2
fmt.Println(foo2.age)
//指针初始化
foo3 := &Foo{}
fmt.Printf("foo3 --> %#v\n ", foo3) //&main.Foo{age:0, name:""}
foo3.age = 3
fmt.Println(foo3.age)
//new 初始化
foo4 := new(Foo)
fmt.Printf("foo4 --> %#v\n ", foo4) //&main.Foo{age:0, name:""}
foo4.age = 4
fmt.Println(foo4.age)
//声明指针并用 new 初始化
var foo5 *Foo = new(Foo)
fmt.Printf("foo5 --> %#v\n ", foo5) //&main.Foo{age:0, name:""}
foo5.age = 5
fmt.Println(foo5.age)
|
foo1 和 foo2 是同样的类型,都是 Foo 类型的值,foo1 是通过 var 声明,Foo 的 filed 自动初始化为每个类型的零值,foo2 是通过字面量的完成初始化。foo3,foo4 和 foo5 是一样的类型,都是 Foo 的指针 Foo。
如果 x 是可寻址的,&x 的 filed 集合包含 m,x.m 和 (&x).m 是等同的,go 自动做转换,也就是 foo1.age 和 foo3.age 调用是等价的,go 在下面自动做了转换。
因而可以直接使用 struct literal 的方式创建对象,能达到和 new 创建是一样的情况而不需要使用 new。
并不是使用new就一定会在堆上分配内存
编译器会自动选择在栈上还是在堆上分配局部变量的存储空间,但可能令人惊讶的是,这个选择并不是由用var还是new声明变量的方式决定的。
1
2
3
4
5
6
7
8
9
10
11
12
|
var global *int
func f() {
var x int
x = 1
global = &x
}
func g() {
y := new(int)
*y = 1
}
|
f函数里的x变量必须在堆上分配,因为它在函数退出后依然可以通过包一级的global变量找到,虽然它是在函数内部定义的;用Go语言的术语说,这个x局部变量从函数f中逃逸了。相反,当g函数返回时,变量*y将是不可达的,也就是说可以马上被回收的。因此,*y并没有从函数g中逃逸,编译器可以选择在栈上分配*y的存储空间(译注:也可以选择在堆上分配,然后由Go语言的GC回收这个变量的内存空间),虽然这里用的是new方式。其实在任何时候,你并不需为了编写正确的代码而要考虑变量的逃逸行为,要记住的是,逃逸的变量需要额外分配内存,同时对性能的优化可能会产生细微的影响。
Go语言的自动垃圾收集器对编写正确的代码是一个巨大的帮助,但也并不是说你完全不用考虑内存了。你虽然不需要显式地分配和释放内存,但是要编写高效的程序你依然需要了解变量的生命周期。例如,如果将指向短生命周期对象的指针保存到具有长生命周期的对象中,特别是保存到全局变量时,会阻止对短生命周期对象的垃圾回收(从而可能影响程序的性能)。
make
在前面的章节中我们已经谈到过 make 在创建切片、哈希表和 Channel 的具体过程,所以在这一小节,我们只是会简单提及 make 相关的数据结构的初始化原理。
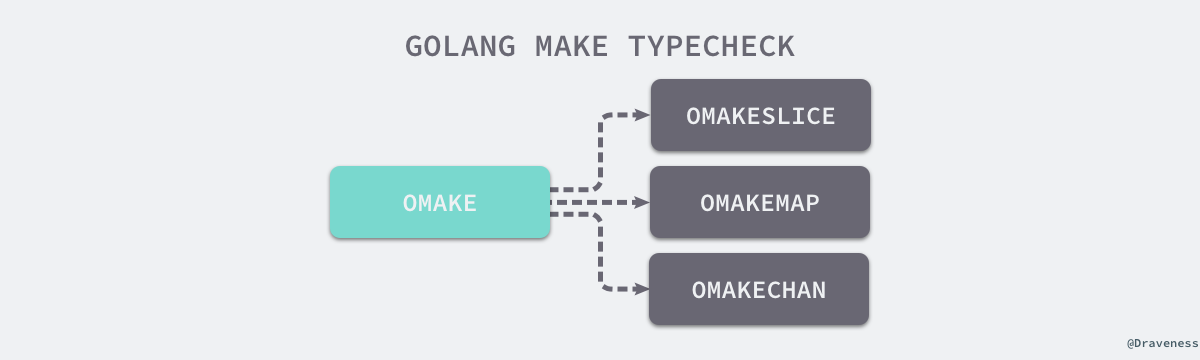
在编译期间的类型检查阶段,Go 语言会将代表 make 关键字的 OMAKE 节点根据参数类型的不同转换成了 OMAKESLICE、OMAKEMAP 和 OMAKECHAN 三种不同类型的节点,这些节点会调用不同的运行时函数来初始化相应的数据结构。
new
编译器会在中间代码生成阶段通过以下两个函数处理该关键字:
cmd/compile/internal/gc.callnew 会将关键字转换成 ONEWOBJ 类型的节点2;cmd/compile/internal/gc.state.expr 会根据申请空间的大小分两种情况处理:
- 如果申请的空间为 0,就会返回一个表示空指针的 zerobase 变量;
- 在遇到其他情况时会将关键字转换成 runtime.newobject 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func callnew(t *types.Type)*Node {
...
n := nod(ONEWOBJ, typename(t), nil)
...
return n
}
func (s *state) expr(n*Node) *ssa.Value {
switch n.Op {
case ONEWOBJ:
if n.Type.Elem().Size() == 0 {
return s.newValue1A(ssa.OpAddr, n.Type, zerobaseSym, s.sb)
}
typ := s.expr(n.Left)
vv := s.rtcall(newobject, true, []*types.Type{n.Type}, typ)
return vv[0]
}
}
|
需要注意的是,无论是直接使用 new,还是使用 var 初始化变量,它们在编译器看来都是 ONEW 和 ODCL 节点。如果变量会逃逸到堆上,这些节点在这一阶段都会被 cmd/compile/internal/gc.walkstmt 转换成通过 runtime.newobject 函数并在堆上申请内存:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
func walkstmt(n *Node)*Node {
switch n.Op {
case ODCL:
v := n.Left
if v.Class() == PAUTOHEAP {
if prealloc[v] == nil {
prealloc[v] = callnew(v.Type)
}
nn := nod(OAS, v.Name.Param.Heapaddr, prealloc[v])
nn.SetColas(true)
nn = typecheck(nn, ctxStmt)
return walkstmt(nn)
}
case ONEW:
if n.Esc == EscNone {
r := temp(n.Type.Elem())
r = nod(OAS, r, nil)
r = typecheck(r, ctxStmt)
init.Append(r)
r = nod(OADDR, r.Left, nil)
r = typecheck(r, ctxExpr)
n = r
} else {
n = callnew(n.Type.Elem())
}
}
}
|
不过这也不是绝对的,如果通过 var 或者 new 创建的变量不需要在当前作用域外生存,例如不用作为返回值返回给调用方,那么就不需要初始化在堆上。
runtime.newobject 函数会获取传入类型占用空间的大小,调用 runtime.mallocgc 在堆上申请一片内存空间并返回指向这片内存空间的指针:
1
2
3
|
func newobject(typ *_type) unsafe.Pointer {
return mallocgc(typ.size, typ, true)
}
|
runtime.mallocgc 函数的实现大概有 200 多行代码,我们会在后面的章节中详细分析 Go 语言的内存管理机制。
小结
这里我们简单总结一下 Go 语言中 make 和 new 关键字的实现原理,make 关键字的作用是创建切片、哈希表和 Channel 等内置的数据结构,而 new 的作用是为类型申请一片内存空间,并返回指向这片内存的指针。
参考
理解 Go make 和 new 的区别
5.5 make 和 new