前言
很多现代的编程语言中都有 defer 关键字,Go 语言的 defer 会在当前函数返回前执行传入的函数,它会经常被用于关闭文件描述符、关闭数据库连接以及解锁资源。这一节会深入 Go 语言的源代码介绍 defer 关键字的实现原理,相信读者读完这一节会对 defer 的数据结构、实现以及调用过程有着更清晰的理解。
作为一个编程语言中的关键字,defer 的实现一定是由编译器和运行时共同完成的,不过在深入源码分析它的实现之前我们还是需要了解 defer 关键字的常见使用场景以及使用时的注意事项。
使用 defer 的最常见场景是在函数调用结束后完成一些收尾工作,例如在 defer 中回滚数据库的事务:
1
2
3
4
5
6
7
8
9
10
|
func createPost(db *gorm.DB) error {
tx := db.Begin()
defer tx.Rollback()
if err := tx.Create(&Post{Author: "Draveness"}).Error; err != nil {
return err
}
return tx.Commit().Error
}
|
在使用数据库事务时,我们可以使用上面的代码在创建事务后就立刻调用 Rollback 保证事务一定会回滚。哪怕事务真的执行成功了,那么调用 tx.Commit() 之后再执行 tx.Rollback() 也不会影响已经提交的事务。
现象
我们在 Go 语言中使用 defer 时会遇到两个常见问题,这里会介绍具体的场景并分析这两个现象背后的设计原理:
- defer 关键字的调用时机以及多次调用 defer 时执行顺序是如何确定的;
- defer 关键字使用传值的方式传递参数时会进行预计算,导致不符合预期的结果;
作用域
向 defer 关键字传入的函数会在函数返回之前运行。假设我们在 for 循环中多次调用 defer 关键字:
1
2
3
4
5
|
func main() {
for i := 0; i < 5; i++ {
defer fmt.Println(i)
}
}
|
1
2
3
4
5
6
|
$ go run main.go
4
3
2
1
0
|
运行上述代码会倒序执行传入 defer 关键字的所有表达式,因为最后一次调用 defer 时传入了 fmt.Println(4),所以这段代码会优先打印 4。我们可以通过下面这个简单例子强化对 defer 执行时机的理解:
1
2
3
4
5
6
7
8
|
func main() {
{
defer fmt.Println("defer runs")
fmt.Println("block ends")
}
fmt.Println("main ends")
}
|
1
2
3
4
5
|
$ go run main.go
block ends
main ends
defer runs
Go
|
从上述代码的输出我们会发现,defer 传入的函数不是在退出代码块的作用域时执行的,它只会在当前函数和方法返回之前被调用。
预计算参数
Go 语言中所有的函数调用都是传值的,虽然 defer 是关键字,但是也继承了这个特性。假设我们想要计算 main 函数运行的时间,可能会写出以下的代码:
1
2
3
4
5
6
|
func main() {
startedAt := time.Now()
defer fmt.Println(time.Since(startedAt))
time.Sleep(time.Second)
}
|
1
2
3
|
$ go run main.go
0s
Go
|
然而上述代码的运行结果并不符合我们的预期,这个现象背后的原因是什么呢?经过分析,我们会发现调用 defer 关键字会立刻拷贝函数中引用的外部参数,所以 time.Since(startedAt) 的结果不是在 main 函数退出之前计算的,而是在 defer 关键字调用时计算的,最终导致上述代码输出 0s。
想要解决这个问题的方法非常简单,我们只需要向 defer 关键字传入匿名函数:
1
2
3
4
5
6
|
func main() {
startedAt := time.Now()
defer func() { fmt.Println(time.Since(startedAt)) }()
time.Sleep(time.Second)
}
|
虽然调用 defer 关键字时也使用值传递,但是因为拷贝的是函数指针,所以 time.Since(startedAt) 会在 main 函数返回前调用并打印出符合预期的结果。
数据结构
一个函数中的延迟语句会被保存为一个 _defer 记录的链表,附着在一个 Goroutine 上。_defer 记录的具体结构也非常简单,主要包含了参与调用的参数大小、 当前 defer 语句所在函数的 PC 和 SP 寄存器、被 defer 的函数的入口地址以及串联 多个 defer 的 link 链表,该链表指向下一个需要执行的 defer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
// A _defer holds an entry on the list of deferred calls.
// If you add a field here, add code to clear it in freedefer and deferProcStack
// This struct must match the code in cmd/compile/internal/gc/reflect.go:deferstruct
// and cmd/compile/internal/gc/ssa.go:(*state).call.
// Some defers will be allocated on the stack and some on the heap.
// All defers are logically part of the stack, so write barriers to
// initialize them are not required. All defers must be manually scanned,
// and for heap defers, marked.
type _defer struct {
// 参数和结果的内存大小
siz int32 // includes both arguments and results
started bool
heap bool
// openDefer indicates that this _defer is for a frame with open-coded
// defers. We have only one defer record for the entire frame (which may
// currently have 0, 1, or more defers active).
// 表示当前 defer 是否经过开放编码的优化;
openDefer bool
// sp 和 pc 分别代表栈指针和调用方的程序计数器;
sp uintptr // sp at time of defer
pc uintptr // pc at time of defer
//fn 是 defer 关键字中传入的函数;
fn *funcval // can be nil for open-coded defers
// _panic 是触发延迟调用的结构体,可能为空;
_panic *_panic // panic that is running defer
link *_defer
// If openDefer is true, the fields below record values about the stack
// frame and associated function that has the open-coded defer(s). sp
// above will be the sp for the frame, and pc will be address of the
// deferreturn call in the function.
fd unsafe.Pointer // funcdata for the function associated with the frame
varp uintptr // value of varp for the stack frame
// framepc is the current pc associated with the stack frame. Together,
// with sp above (which is the sp associated with the stack frame),
// framepc/sp can be used as pc/sp pair to continue a stack trace via
// gentraceback().
framepc uintptr
}
|
runtime._defer 结构体是延迟调用链表上的一个元素,所有的结构体都会通过 link 字段串联成链表。

执行机制
延迟语句的文法产生式 DeferStmt -> "defer" Expression 的描述非常的简单,因而也 很容易将其处理为语法树的形式,但我们这里更关心的其实是它语义背后的中间和目标代码的形式。
在进行中间代码生成阶段时,会通过 compileSSA 先调用 buildssa 为函数体生成 SSA 形式的函数, 并而后调用 genssa 将函数的 SSA 中间表示转换为具体的指令。
Go 语言的语句在执行 buildssa 阶段中,会由 state.stmt 完成函数中各个语句 SSA 处理。
中间代码生成阶段的 cmd/compile/internal/gc.state.stmt 会负责处理程序中的 defer,该函数会根据条件的不同,使用三种不同的机制处理该关键字:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
func (s *state) stmt(n*Node) {
...
switch n.Op {
case ODEFER:
if Debug_defer > 0 {
var defertype string
if s.hasOpenDefers {
defertype = "open-coded"
} else if n.Esc == EscNever {
defertype = "stack-allocated"
} else {
defertype = "heap-allocated"
}
Warnl(n.Pos, "%s defer", defertype)
}
// 开放编码式 defer
if s.hasOpenDefers {
s.openDeferRecord(n.Left)
} else {
// 堆上分配的 defer
d := callDefer
if n.Esc == EscNever {
// 栈上分配的 defer
d = callDeferStack
}
s.callResult(n.Left, d)
}
...
}
}
|
对于延迟语句而言,其中间表示会产生三种不同的延迟形式,第一种是最一般情况下的在堆上分配的延迟语句,第二种是允许在栈上分配的延迟语句, 最后一种则是开放编码式(Open-coded)的延迟语句。
堆分配、栈分配和开放编码是处理 defer 关键字的三种方法,早期的 Go 语言会在堆上分配 runtime._defer 结构体,不过该实现的性能较差,Go 语言在 1.13 中引入栈上分配的结构体,减少了 30% 的额外开销,并在 1.14 中引入了基于开放编码的 defer,使得该关键字的额外开销可以忽略不计,我们在一节中会分别介绍三种不同类型 defer 的设计与实现原理。
堆上分配
我们先来讨论最简单的在堆上分配的 defer 这种形式。在堆上分配的原因是 defer 语句出现 在了循环语句里,或者无法执行更高阶的编译器优化导致的。如果一个与 defer 出现在循环语句中, 则可执行的次数可能无法在编译期决定;如果一个调用中 defer 由于数量过多等原因, 不能被编译器进行开放编码,则也会在堆上分配 defer。
总之,由于这种不确定性的存在,在堆上分配的 defer 需要最多的运行时支持, 因而产生的运行时开销也最大。
编译阶段
为了使延迟语句的功能满足语言规范,该语句在编译的 SSA 阶段会被翻译为两个主体, 其中第一个主体是被延迟的函数本身,另一个主体则是函数结束时需要执行所记录 defer 的代码块。
state.call 调用会生成用于记录延迟调用参数的指令,并创建一个 deferproc 的调用指令; 而后在 state.exit 调用在函数返回前插入 deferreturn 调用的指令。
根据 cmd/compile/internal/gc.state.stmt 方法对 defer 的处理我们可以看出,堆上分配的 runtime._defer 结构体是默认的兜底方案,当该方案被启用时,编译器会调用 cmd/compile/internal/gc.state.callResult 和 cmd/compile/internal/gc.state.call,这表示 defer 在编译器看来也是函数调用。
cmd/compile/internal/gc.state.call 会负责为所有函数和方法调用生成中间代码,它的工作包括以下内容:
- 获取需要执行的函数名、闭包指针、代码指针和函数调用的接收方;
- 获取栈地址并将函数或者方法的参数写入栈中;
- 使用
cmd/compile/internal/gc.state.newValue1A 以及相关函数生成函数调用的中间代码;
- 如果当前调用的函数是 defer,那么会单独生成相关的结束代码块;
- 获取函数的返回值地址并结束当前调用;
编译器不仅将 defer 关键字都转换成 runtime.deferproc 函数,它还会通过以下三个步骤为所有调用 defer 的函数末尾插入 runtime.deferreturn 的函数调用:
cmd/compile/internal/gc.walkstmt 在遇到 ODEFER 节点时会执行 Curfn.Func.SetHasDefer(true) 设置当前函数的 hasdefer 属性;cmd/compile/internal/gc.buildssa 会执行 s.hasdefer = fn.Func.HasDefer() 更新 state 的 hasdefer;cmd/compile/internal/gc.state.exit 会根据 state 的 hasdefer 在函数返回之前插入 runtime.deferreturn 的函数调用;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
// src/cmd/compile/internal/gc/ssa.go
func (s *state) call(n *Node, k callKind) *ssa.Value {
...
var call *ssa.Value
if k == callDeferStack {
...
} else {
// 在堆上创建 defer
argStart := Ctxt.FixedFrameSize()
// Defer 参数
if k != callNormal {
// 记录 deferproc 的参数
argsize := s.constInt32(types.Types[TUINT32], int32(stksize))
addr := s.constOffPtrSP(s.f.Config.Types.UInt32Ptr, argStart)
s.store(types.Types[TUINT32], addr, argsize) // 保存参数大小 siz
addr = s.constOffPtrSP(s.f.Config.Types.UintptrPtr, argStart+int64(Widthptr))
s.store(types.Types[TUINTPTR], addr, closure) // 保存函数地址 fn
stksize += 2 * int64(Widthptr)
argStart += 2 * int64(Widthptr)
}
...
// 创建 deferproc 调用
switch {
case k == callDefer:
call = s.newValue1A(ssa.OpStaticCall, types.TypeMem, deferproc, s.mem())
...
}
...
}
...
// 结束 defer 块
if k == callDefer || k == callDeferStack {
s.exit()
...
}
...
}
func (s *state) exit() *ssa.Block {
if s.hasdefer {
if s.hasOpenDefers {
...
} else {
// 调用 deferreturn
s.rtcall(Deferreturn, true, nil)
}
}
...
}
|
从上述代码中我们能看到,defer 关键字在运行期间会调用 runtime.deferproc,这个函数接收了参数的大小和闭包所在的地址两个参数。
当运行时将 runtime._defer 分配到堆上时,Go 语言的编译器不仅将 defer 转换成了 runtime.deferproc,还在所有调用 defer 的函数结尾插入了 runtime.deferreturn。上述两个运行时函数是 defer 关键字运行时机制的入口,它们分别承担了不同的工作:
runtime.deferproc 负责创建新的延迟调用;runtime.deferreturn 负责在函数调用结束时执行所有的延迟调用;
我们以上述两个函数为入口介绍 defer 关键字在运行时的执行过程与工作原理。
例如,对于一个纯粹的 defer 调用而言:
1
2
3
4
5
6
7
8
9
10
|
package main
func foo() {
return
}
func main() {
defer foo()
return
}
|
如果我们将其强制编译为在堆上分配的形式,可以观察到如下的汇编代码。其中 defer foo() 被转化为了 deferproc 调用,并在函数返回前,调用了 deferreturn:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
TEXT main.foo(SB) /Users/changkun/Desktop/defer/ssa/main.go
return
0x104ea20 c3 RET
TEXT main.main(SB) /Users/changkun/Desktop/defer/ssa/main.go
func main() {
...
// 将 defer foo() { ... }() 转化为一个 deferproc 调用
// 在调用 deferproc 前完成参数的准备工作,这个例子中没有参数
0x104ea4d c7042400000000 MOVL $0x0, 0(SP)
0x104ea54 488d0585290200 LEAQ go.func.*+60(SB), AX
0x104ea5b 4889442408 MOVQ AX, 0x8(SP)
0x104ea60 e8bb31fdff CALL runtime.deferproc(SB)
...
// 函数返回指令 RET 前插入的 deferreturn 语句
0x104ea7b 90 NOPL
0x104ea7c e82f3afdff CALL runtime.deferreturn(SB)
0x104ea81 488b6c2410 MOVQ 0x10(SP), BP
0x104ea86 4883c418 ADDQ $0x18, SP
0x104ea8a c3 RET
// 函数的尾声
0x104ea8b e8d084ffff CALL runtime.morestack_noctxt(SB)
0x104ea90 eb9e JMP main.main(SB)
|
deferproc
runtime.deferproc 会为 defer 创建一个新的 runtime._defer 结构体、设置它的函数指针 fn、程序计数器 pc 和栈指针 sp 并将相关的参数拷贝到相邻的内存空间中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func deferproc(siz int32, fn *funcval) {
sp := getcallersp()
argp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn)
callerpc := getcallerpc()
d := newdefer(siz)
if d._panic != nil {
throw("deferproc: d.panic != nil after newdefer")
}
d.fn = fn
d.pc = callerpc
d.sp = sp
// 将参数保存到 _defer 记录中
switch siz {
case 0: // 什么也不做
case sys.PtrSize:
*(*uintptr)(deferArgs(d)) = *(*uintptr)(unsafe.Pointer(argp))
default:
memmove(deferArgs(d), unsafe.Pointer(argp), uintptr(siz))
}
return0()
}
|
最后调用的 runtime.return0 是唯一一个不会触发延迟调用的函数,它可以避免递归 runtime.deferreturn 的递归调用。
这段代码中,本质上只是在做一些简单参数处理, 比如 fn 保存了 defer 所调用函数的调用地址,siz 确定了其参数的大小。 并且通过 newdefer 来创建一个新的 _defer 实例, 然后由 fn、callerpc 和 sp 来保存调用该 defer 的 Goroutine 上下文。
注意,在这里我们看到了一个对参数进行拷贝的操作。这个操作也是我们在实践过程中经历过的, defer 调用被记录时,并不会对参数进行求值,而是会对参数完成一次拷贝。 这么做原因是由于语义上的考虑。直觉上讲,defer 的参数应当在它所写的位置对传入的参数 进行求值,而不是将求值步骤推迟,因为延后的参数可能发生变化,导致 defer 的语义发生意料之外的错误。 例如,f, _ := os.Open("file.txt") 后立刻指定 defer f.Close(),倘若随后的语句修改了 f 的值,那么将导致 f 无法被正常关闭。
出于性能考虑,newdefer 通过 P 或者调度器 sched 上的本地或全局 defer 池来 复用已经在堆上分配的内存。defer 的资源池会根据被延迟的调用所需的参数来决定 defer 记录 的大小等级,每 16 个字节分一个等级。
runtime.deferproc 中 runtime.newdefer 的作用是想尽办法获得 runtime._defer 结构体,这里包含三种路径:
- 从调度器的延迟调用缓存池 sched.deferpool 中取出结构体并将该结构体追加到当前 Goroutine 的缓存池中;
- 从 Goroutine 的延迟调用缓存池 pp.deferpool 中取出结构体;
- 通过 runtime.mallocgc 在堆上创建一个新的结构体;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
// src/runtime/runtime2.go
type p struct {
...
// 不同大小的本地 defer 池
deferpool [5][]*_defer
deferpoolbuf [5][32]*_defer
...
}
type schedt struct {
...
// 不同大小的全局 defer 池
deferlock mutex
deferpool [5]*_defer
...
}
// Allocate a Defer, usually using per-P pool.
// Each defer must be released with freedefer. The defer is not
// added to any defer chain yet.
//
// This must not grow the stack because there may be a frame without
// stack map information when this is called.
//
//go:nosplit
func newdefer(siz int32) *_defer {
var d *_defer
sc := deferclass(uintptr(siz))
gp := getg()
// 检查 defer 参数的大小是否从 p 的 deferpool 直接分配
if sc < uintptr(len(p{}.deferpool)) {
pp := gp.m.p.ptr()
// 如果 p 本地无法分配,则从全局池中获取一半 defer,来填充 P 的本地资源池
if len(pp.deferpool[sc]) == 0 && sched.deferpool[sc] != nil {
// Take the slow path on the system stack so
// we don't grow newdefer's stack.
// 出于性能考虑,如果发生栈的增长,则会调用 morestack,
// 进一步降低 defer 的性能。因此切换到系统栈上执行,进而不会发生栈的增长。
systemstack(func() {
lock(&sched.deferlock)
for len(pp.deferpool[sc]) < cap(pp.deferpool[sc])/2 && sched.deferpool[sc] != nil {
d := sched.deferpool[sc]
sched.deferpool[sc] = d.link
d.link = nil
pp.deferpool[sc] = append(pp.deferpool[sc], d)
}
unlock(&sched.deferlock)
})
}
// 从 P 本地进行分配
if n := len(pp.deferpool[sc]); n > 0 {
d = pp.deferpool[sc][n-1]
pp.deferpool[sc][n-1] = nil
pp.deferpool[sc] = pp.deferpool[sc][:n-1]
}
}
// 没有可用的缓存,直接从堆上分配新的 defer 和 args
if d == nil {
// Allocate new defer+args.
systemstack(func() {
total := roundupsize(totaldefersize(uintptr(siz)))
d = (*_defer)(mallocgc(total, deferType, true))
})
}
// 将 _defer 实例添加到 Goroutine 的 _defer 链表上。
d.siz = siz
d.heap = true
return d
}
|
无论使用哪种方式,只要获取到 runtime._defer 结构体,它都会被追加到所在 Goroutine_defer 链表的最前面。
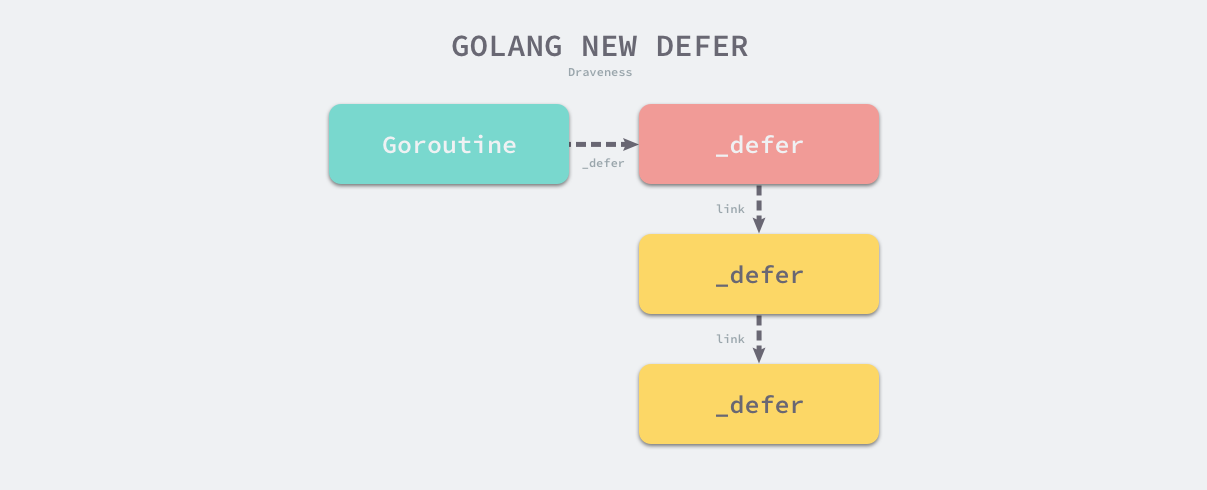
defer 关键字的插入顺序是从后向前的,而 defer 关键字执行是从前向后的,这也是为什么后调用的 defer 会优先执行。
deferreturn
deferreturn 被编译器插入到函数末尾,当跳转到它时,会将需要被 defer 的入口地址取出, 然后跳转并执行:
runtime.deferreturn 会从 Goroutine 的 _defer 链表中取出最前面的 runtime._defer 并调用 runtime.jmpdefer 传入需要执行的函数和参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
// Run a deferred function if there is one.
// The compiler inserts a call to this at the end of any
// function which calls defer.
// If there is a deferred function, this will call runtime·jmpdefer,
// which will jump to the deferred function such that it appears
// to have been called by the caller of deferreturn at the point
// just before deferreturn was called. The effect is that deferreturn
// is called again and again until there are no more deferred functions.
//
// Declared as nosplit, because the function should not be preempted once we start
// modifying the caller's frame in order to reuse the frame to call the deferred
// function.
//
// The single argument isn't actually used - it just has its address
// taken so it can be matched against pending defers.
//go:nosplit
func deferreturn(arg0 uintptr) {
gp := getg()
d := gp._defer
if d == nil {
return
}
// 确定 defer 的调用方是不是当前 deferreturn 的调用方
sp := getcallersp()
if d.sp != sp {
return
}
if d.openDefer {
done := runOpenDeferFrame(gp, d)
if !done {
throw("unfinished open-coded defers in deferreturn")
}
gp._defer = d.link
freedefer(d)
return
}
// Moving arguments around.
//
// Everything called after this point must be recursively
// nosplit because the garbage collector won't know the form
// of the arguments until the jmpdefer can flip the PC over to
// fn.
// 将参数复制出 _defer 记录外
switch d.siz {
case 0: // 什么也不做
// Do nothing.
case sys.PtrSize:
*(*uintptr)(unsafe.Pointer(&arg0)) = *(*uintptr)(deferArgs(d))
default:
memmove(unsafe.Pointer(&arg0), deferArgs(d), uintptr(d.siz))
}
// 获得被延迟的调用 fn 的入口地址,并随后立即将 _defer 释放掉
fn := d.fn
d.fn = nil
gp._defer = d.link
freedefer(d)
// If the defer function pointer is nil, force the seg fault to happen
// here rather than in jmpdefer. gentraceback() throws an error if it is
// called with a callback on an LR architecture and jmpdefer is on the
// stack, because the stack trace can be incorrect in that case - see
// issue #8153).
_ = fn.fn
// 调用,并跳转到下一个 defer
jmpdefer(fn, uintptr(unsafe.Pointer(&arg0)))
}
|
在这个函数中,会在需要时对 defer 的参数再次进行拷贝,多个 defer 函数以 jmpdefer 尾调用形式被实现。 在跳转到 fn 之前,_defer 实例被释放归还,jmpdefer 真正需要的仅仅只是函数的入口地址和参数, 以及它的调用方 deferreturn 的 SP:
runtime.jmpdefer 是一个用汇编语言实现的运行时函数,它的主要工作是跳转到 defer 所在的代码段并在执行结束之后跳转回 runtime.deferreturn。
1
2
3
4
5
6
7
8
9
10
11
|
// src/runtime/asm_amd64.s
// func jmpdefer(fv *funcval, argp uintptr)
TEXT runtime·jmpdefer(SB), NOSPLIT, $0-16
MOVQ fv+0(FP), DX // DX = fn
MOVQ argp+8(FP), BX // 调用方 SP
LEAQ -8(BX), SP // CALL 后的调用方 SP
MOVQ -8(SP), BP // 恢复 BP,好像 deferreturn 返回
SUBQ $5, (SP) // 再次返回到 CALL
MOVQ 0(DX), BX // BX = DX
JMP BX // 最后才运行被 defer 的函数
|
这个 jmpdefer 巧妙的地方在于,它通过调用方 SP 来推算了 deferreturn 的入口地址, 从而在完成某个 defer 调用后,由于被 defer 的函数返回时会出栈, 会再次回到 deferreturn 的初始位置,进而继续反复调用,从而模拟 deferreturn 不断的对自己进行尾递归的假象。
runtime.deferreturn 会多次判断当前 Goroutine 的_defer 链表中是否有未执行的结构体,该函数只有在所有延迟函数都执行后才会返回。
freedefer
释放操作非常普通,只是简单的将其归还到 P 的 deferpool 中, 并在本地池已满时将其归还到全局资源池:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
// Free the given defer.
// The defer cannot be used after this call.
//
// This must not grow the stack because there may be a frame without a
// stack map when this is called.
//
//go:nosplit
func freedefer(d *_defer) {
if d._panic != nil {
freedeferpanic()
}
if d.fn != nil {
freedeferfn()
}
if !d.heap {
return
}
sc := deferclass(uintptr(d.siz))
if sc >= uintptr(len(p{}.deferpool)) {
return
}
pp := getg().m.p.ptr()
// 如果 P 本地池已满,则将一半资源放入全局池,同样也是出于性能考虑
// 操作会切换到系统栈上执行。
if len(pp.deferpool[sc]) == cap(pp.deferpool[sc]) {
// Transfer half of local cache to the central cache.
//
// Take this slow path on the system stack so
// we don't grow freedefer's stack.
systemstack(func() {
var first, last *_defer
for len(pp.deferpool[sc]) > cap(pp.deferpool[sc])/2 {
n := len(pp.deferpool[sc])
d := pp.deferpool[sc][n-1]
pp.deferpool[sc][n-1] = nil
pp.deferpool[sc] = pp.deferpool[sc][:n-1]
if first == nil {
first = d
} else {
last.link = d
}
last = d
}
lock(&sched.deferlock)
last.link = sched.deferpool[sc]
sched.deferpool[sc] = first
unlock(&sched.deferlock)
})
}
// These lines used to be simply `*d = _defer{}` but that
// started causing a nosplit stack overflow via typedmemmove.
// 恢复 _defer 的零值,即 *d = _defer{}
d.siz = 0
d.started = false
d.openDefer = false
d.sp = 0
d.pc = 0
d.framepc = 0
d.varp = 0
d.fd = nil
// d._panic and d.fn must be nil already.
// If not, we would have called freedeferpanic or freedeferfn above,
// both of which throw.
d.link = nil
// 放入 P 本地资源池
pp.deferpool[sc] = append(pp.deferpool[sc], d)
}
|
栈上分配
Go 语言团队在 1.13 中对 defer 关键字进行了优化,当该关键字在函数体中最多执行一次时,编译期间的 cmd/compile/internal/gc.state.call 会将结构体分配到栈上并调用 runtime.deferprocStack:
defer 还可以直接在栈上进行分配,也就是第二种记录 defer 的形式 deferprocStack。 在栈上分配 defer 的好处在于函数返回后 _defer 便已得到释放, 不再需要考虑内存分配时产生的性能开销,只需要适当的维护_defer 的链表即可。
在 SSA 阶段与在堆上分配的区别在于,在栈上创建 defer, 需要直接在函数调用帧上使用编译器来初始化 _defer 记录,并作为参数传递给 deferprocStack:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
// src/cmd/compile/internal/gc/ssa.go
func (s *state) call(n *Node, k callKind) *ssa.Value {
...
var call *ssa.Value
if k == callDeferStack {
// 直接在栈上创建 defer 记录
t := deferstruct(stksize) // 从编译器角度构造 _defer 结构
d := tempAt(n.Pos, s.curfn, t)
s.vars[&memVar] = s.newValue1A(ssa.OpVarDef, types.TypeMem, d, s.mem())
addr := s.addr(d, false)
// 在栈上预留记录 _defer 的各个字段的空间
s.store(types.Types[TUINT32],
s.newValue1I(ssa.OpOffPtr, types.Types[TUINT32].PtrTo(), t.FieldOff(0), addr),
s.constInt32(types.Types[TUINT32], int32(stksize)))
s.store(closure.Type,
s.newValue1I(ssa.OpOffPtr, closure.Type.PtrTo(), t.FieldOff(6), addr),
closure)
// 记录参与 defer 调用的函数参数
ft := fn.Type
off := t.FieldOff(12)
args := n.Rlist.Slice()
// 调用 deferprocStack,以 _defer 记录的指针作为参数传递
arg0 := s.constOffPtrSP(types.Types[TUINTPTR], Ctxt.FixedFrameSize())
s.store(types.Types[TUINTPTR], arg0, addr)
call = s.newValue1A(ssa.OpStaticCall, types.TypeMem, deferprocStack, s.mem())
...
} else { ... }
// 函数尾声与堆上分配的栈一样,调用 deferreturn
if k == callDefer || k == callDeferStack {
...
s.exit()
}
...
}
|
可见,在编译阶段,一个 _defer 记录的空间已经在栈上得到保留,deferprocStack 的作用 就仅仅承担了运行时对该记录的初始化这一功能:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// src/runtime/panic.go
//go:nosplit
func deferprocStack(d *_defer) {
gp := getg()
// 注意,siz 和 fn 已经在编译阶段完成设置,这里只初始化了其他字段
d.started = false
d.heap = false // 可见此时 defer 被标记为不在堆上分配
d.openDefer = false
d.sp = getcallersp()
d.pc = getcallerpc()
...
// 尽管在栈上进行分配,仍然需要将多个 _defer 记录通过链表进行串联,
// 以便在 deferreturn 中找到被延迟的函数的入口地址:
// d.link = gp._defer
// gp._defer = d
*(*uintptr)(unsafe.Pointer(&d.link)) = uintptr(unsafe.Pointer(gp._defer))
*(*uintptr)(unsafe.Pointer(&gp._defer)) = uintptr(unsafe.Pointer(d))
return0()
}
|
至于函数尾声的行为,与在堆上进行分配的操作同样是调用 deferreturn,我们就不再重复说明了。 当然,里面涉及的 freedefer 调用由于不需要释放任何内存,也就早早返回了:
1
2
3
4
5
|
// src/runtime/panic.go
func freedefer(d *_defer) {
if !d.heap { return }
...
}
|
除了分配位置的不同,栈上分配和堆上分配的 runtime._defer 并没有本质的不同,而该方法可以适用于绝大多数的场景,与堆上分配的 runtime._defer 相比,该方法可以将 defer 关键字的额外开销降低 ~30%。
开放编码
defer 给我们的第一感觉其实是一个编译期特性。前面我们讨论了 为什么 defer 会需要运行时的支持,以及需要运行时的 defer 是如何工作的。现在我们来 探究一下什么情况下能够让 defer 进化为一个仅编译期特性,即在函数末尾直接对延迟函数进行调用, 做到几乎不需要额外的开销。这类几乎不需要额外运行时性能开销的 defer,正是开放编码式 defer。 这类 defer 与直接调用产生的性能差异有多大呢?我们不妨编写两个性能测试:
1
2
3
4
5
6
7
|
func call() { func() {}() }
func callDefer() { defer func() {}() }
func BenchmarkDefer(b *testing.B) {
for i := 0; i < b.N; i++ {
call() // 第二次运行时替换为 callDefer
}
}
|
在 Go 1.14 版本下,读者可以获得类似下方的性能估计,其中使用 callDefer 后, 性能损耗大约为 1 ns。这种纳秒级的性能损耗不到一个 CPU 时钟周期, 我们已经可以认为开放编码式 defer 几乎没有了性能开销:
1
2
|
name old time/op new time/op delta
Defer-12 1.24ns ± 1% 2.23ns ± 1% +80.06% (p=0.000 n=10+9)
|
我们再来观察一下开放编码式 defer 最终被编译的形式:
1
2
|
go build -gcflags "-l" -ldflags=-compressdwarf=false -o main.out main.go
go tool objdump -S main.out > main.s
|
对于如下形式的函数调用:
1
2
3
4
5
|
var mu sync.Mutex
func callDefer() {
mu.Lock()
defer mu.Unlock()
}
|
整个调用最终编译结果既没有 deferproc 或者 deferprocStack,也没有了 deferreturn。 延迟语句被直接插入到了函数的末尾:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
TEXT main.callDefer(SB) /Users/changkun/Desktop/defer/main.go
func callDefer() {
...
mu.Lock()
0x105794a 488d05071f0a00 LEAQ main.mu(SB), AX
0x1057951 48890424 MOVQ AX, 0(SP)
0x1057955 e8f6f8ffff CALL sync.(*Mutex).Lock(SB)
defer mu.Unlock()
0x105795a 488d057f110200 LEAQ go.func.*+1064(SB), AX
0x1057961 4889442418 MOVQ AX, 0x18(SP)
0x1057966 488d05eb1e0a00 LEAQ main.mu(SB), AX
0x105796d 4889442410 MOVQ AX, 0x10(SP)
}
0x1057972 c644240f00 MOVB $0x0, 0xf(SP)
0x1057977 488b442410 MOVQ 0x10(SP), AX
0x105797c 48890424 MOVQ AX, 0(SP)
0x1057980 e8ebfbffff CALL sync.(*Mutex).Unlock(SB)
0x1057985 488b6c2420 MOVQ 0x20(SP), BP
0x105798a 4883c428 ADDQ $0x28, SP
0x105798e c3 RET
...
|
那么开放编码式 defer 是怎么实现的?所有的 defer 都是开放编码式的吗? 什么情况下,开放编码式 defer 会退化为一个依赖运行时的特性?
Go 语言在 1.14 中通过开放编码(Open Coded)实现 defer 关键字,该设计使用代码内联优化 defer 关键的额外开销并引入函数数据 funcdata 管理 panic 的调用,该优化可以将 defer 的调用开销从 1.13 版本的 ~35ns 降低至 ~6ns 左右:
1
2
3
|
With normal (stack-allocated) defers only: 35.4 ns/op
With open-coded defers: 5.6 ns/op
Cost of function call alone (remove defer keyword): 4.4 ns/op
|
启动条件
我们先来看开放编码式 defer 的启动条件。在 SSA 的构建阶段 buildssa,我们有:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
// src/cmd/compile/internal/gc/ssa.go
const maxOpenDefers = 8
func walkstmt(n *Node) *Node {
...
switch n.Op {
case ODEFER:
Curfn.Func.SetHasDefer(true)
Curfn.Func.numDefers++
// 超过 8 个 defer 时,禁用对 defer 进行开放编码
if Curfn.Func.numDefers > maxOpenDefers {
Curfn.Func.SetOpenCodedDeferDisallowed(true)
}
// 存在循环语句中的 defer,禁用对 defer 进行开放编码。
// 是否有 defer 发生在循环语句内,会在 SSA 之前的逃逸分析中进行判断,
// 逃逸分析会检查是否存在循环(loopDepth):
// if where.Op == ODEFER && e.loopDepth == 1 {
// where.Esc = EscNever
// ...
// }
if n.Esc != EscNever {
Curfn.Func.SetOpenCodedDeferDisallowed(true)
}
case ...
}
...
}
func buildssa(fn *Node, worker int) *ssa.Func {
...
var s state
...
s.hasdefer = fn.Func.HasDefer()
...
// 可以对 defer 进行开放编码的条件
s.hasOpenDefers = Debug['N'] == 0 && s.hasdefer && !s.curfn.Func.OpenCodedDeferDisallowed()
if s.hasOpenDefers &&
s.curfn.Func.numReturns*s.curfn.Func.numDefers > 15 {
s.hasOpenDefers = false
}
...
}
|
这样,我们得到了允许进行 defer 的开放编码的主要条件 (此处略去了一些常见生产环境无关的条件,例如启用竞争检查时也不能对 defer 进行开放编码):
- 没有禁用编译器优化,即没有设置
-gcflags "-N"
- 存在 defer 调用
- 函数内 defer 的数量不超过 8 个、且返回语句与延迟语句个数的乘积不超过 15
- 没有与 defer 发生在循环语句中
延迟比特
当然,正常编写的 defer 可以直接被编译器分析得出,但是如本节开头提到的,如果一个 defer 发生在一个条件语句中,而这个条件必须等到运行时才能确定:
1
2
3
|
if rand.Intn(100) < 42 {
defer fmt.Println("meaning-of-life")
}
|
那么如何才能使用最小的成本,让插入到函数末尾的延迟语句,在条件成立时候被正确执行呢? 这便需要一种机制,能够记录存在延迟语句的条件分支是否被执行, 这种机制在 Go 中利用了延迟比特(defer bit)。这种做法非常巧妙,但原理却非常简单。
对于下面的代码而言:
1
2
3
4
5
|
defer f1(a1)
if cond {
defer f2(a2)
}
...
|
使用延迟比特的核心思想可以用下面的伪代码来概括。 在创建延迟调用的阶段,首先通过延迟比特的特定位置记录哪些带条件的 defer 被触发。 这个延迟比特是一个长度为 8 位的二进制码(也是硬件架构里最小、最通用的情况), 以每一位是否被设置为 1,来判断延迟语句是否在运行时被设置,如果设置,则发生调用。 否则则不调用:
1
2
3
4
5
6
7
8
9
10
|
deferBits = 0 // 初始值 00000000
deferBits |= 1 << 0 // 遇到第一个 defer,设置为 00000001
_f1 = f1
_a1 = a1
if cond {
// 如果第二个 defer 被设置,则设置为 00000011,否则依然为 00000001
deferBits |= 1 << 1
_f2 = f2
_a2 = a2
}
|
在退出位置,再重新根据被标记的延迟比特,反向推导哪些位置的 defer 需要被触发,从而 执行延迟调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
exit:
// 按顺序倒序检查延迟比特。如果第二个 defer 被设置,则
// 00000011 & 00000010 == 00000010,即延迟比特不为零,应该调用 f2。
// 如果第二个 defer 没有被设置,则
// 00000001 & 00000010 == 00000000,即延迟比特为零,不应该调用 f2。
if deferBits & 1 << 1 != 0 { // 00000011 & 00000010 != 0
deferBits &^= 1<<1 // 00000001
_f2(_a2)
}
// 同理,由于 00000001 & 00000001 == 00000001,因此延迟比特不为零,应该调用 f1
if deferBits && 1 << 0 != 0 {
deferBits &^= 1<<0
_f1(_a1)
}
|
在实际的实现中,可以看到,当可以设置开放编码式 defer 时,buildssa 会首先创建一个 长度位 8 位的临时变量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// src/cmd/compile/internal/gc/ssa.go
func buildssa(fn *Node, worker int) *ssa.Func {
...
if s.hasOpenDefers {
// 创建 deferBits 临时变量
deferBitsTemp := tempAt(src.NoXPos, s.curfn, types.Types[TUINT8])
s.deferBitsTemp = deferBitsTemp
// deferBits 被设计为 8 位二进制,因此可以被开放编码的 defer 数量不能超过 8 个
// 此处还将起始 deferBits 设置为零
startDeferBits := s.entryNewValue0(ssa.OpConst8, types.Types[TUINT8])
s.vars[&deferBitsVar] = startDeferBits
s.deferBitsAddr = s.addr(deferBitsTemp, false)
s.store(types.Types[TUINT8], s.deferBitsAddr, startDeferBits)
...
}
...
s.stmtList(fn.Nbody) // 调用 s.stmt
...
}
|
随后针对出现 defer 的语句,进行编码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
// src/cmd/compile/internal/gc/ssa.go
func (s *state) stmt(n *Node) {
...
switch n.Op {
case ODEFER:
// 开放编码式 defer
if s.hasOpenDefers {
s.openDeferRecord(n.Left)
} else { ... }
case ...
}
...
}
// 存储一个 defer 调用的相关信息,例如所在的语法树结点、被延迟的调用、参数等等
type openDeferInfo struct {
n *Node
closure *ssa.Value
closureNode *Node
...
argVals []*ssa.Value
argNodes []*Node
}
func (s *state) openDeferRecord(n *Node) {
...
var args []*ssa.Value
var argNodes []*Node
// 记录与 defer 相关的入口地址与参数信息
opendefer := &openDeferInfo{n: n}
fn := n.Left
// 记录函数入口地址
if n.Op == OCALLFUNC {
closureVal := s.expr(fn)
closure := s.openDeferSave(nil, fn.Type, closureVal)
opendefer.closureNode = closure.Aux.(*Node)
if !(fn.Op == ONAME && fn.Class() == PFUNC) {
opendefer.closure = closure
}
} else {
...
}
// 记录需要立即求值的的参数
for _, argn := range n.Rlist.Slice() {
var v *ssa.Value
if canSSAType(argn.Type) {
v = s.openDeferSave(nil, argn.Type, s.expr(argn))
} else {
v = s.openDeferSave(argn, argn.Type, nil)
}
args = append(args, v)
argNodes = append(argNodes, v.Aux.(*Node))
}
opendefer.argVals = args
opendefer.argNodes = argNodes
// 每多出现一个 defer,len(defers) 会增加,进而
// 延迟比特 deferBits |= 1<<len(defers) 被设置在不同的位上
index := len(s.openDefers)
s.openDefers = append(s.openDefers, opendefer)
bitvalue := s.constInt8(types.Types[TUINT8], 1<<uint(index))
newDeferBits := s.newValue2(ssa.OpOr8, types.Types[TUINT8], s.variable(&deferBitsVar, types.Types[TUINT8]), bitvalue)
s.vars[&deferBitsVar] = newDeferBits
s.store(types.Types[TUINT8], s.deferBitsAddr, newDeferBits)
}
|
在函数返回退出前,state 的 exit 函数会依次倒序创建对延迟比特的检查代码, 从而顺序调用被延迟的函数调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
// src/cmd/compile/internal/gc/ssa.go
func (s *state) exit() *ssa.Block {
if s.hasdefer {
if s.hasOpenDefers {
...
s.openDeferExit()
} else {
...
}
}
...
}
func (s *state) openDeferExit() {
deferExit := s.f.NewBlock(ssa.BlockPlain)
s.endBlock().AddEdgeTo(deferExit)
s.startBlock(deferExit)
s.lastDeferExit = deferExit
s.lastDeferCount = len(s.openDefers)
zeroval := s.constInt8(types.Types[TUINT8], 0)
// 倒序检查 defer
for i := len(s.openDefers) - 1; i >= 0; i-- {
r := s.openDefers[i]
bCond := s.f.NewBlock(ssa.BlockPlain)
bEnd := s.f.NewBlock(ssa.BlockPlain)
// 检查 deferBits
deferBits := s.variable(&deferBitsVar, types.Types[TUINT8])
// 创建 if deferBits & 1 << len(defer) != 0 { ... }
bitval := s.constInt8(types.Types[TUINT8], 1<<uint(i))
andval := s.newValue2(ssa.OpAnd8, types.Types[TUINT8], deferBits, bitval)
eqVal := s.newValue2(ssa.OpEq8, types.Types[TBOOL], andval, zeroval)
b := s.endBlock()
b.Kind = ssa.BlockIf
b.SetControl(eqVal)
b.AddEdgeTo(bEnd)
b.AddEdgeTo(bCond)
bCond.AddEdgeTo(bEnd)
s.startBlock(bCond)
// 如果创建的条件分支被触发,则清空当前的延迟比特: deferBits &^= 1 << len(defers)
nbitval := s.newValue1(ssa.OpCom8, types.Types[TUINT8], bitval)
maskedval := s.newValue2(ssa.OpAnd8, types.Types[TUINT8], deferBits, nbitval)
s.store(types.Types[TUINT8], s.deferBitsAddr, maskedval)
s.vars[&deferBitsVar] = maskedval
// 处理被延迟的函数调用,取出保存的入口地址、参数信息
argStart := Ctxt.FixedFrameSize()
fn := r.n.Left
stksize := fn.Type.ArgWidth()
...
for j, argAddrVal := range r.argVals {
f := getParam(r.n, j)
pt := types.NewPtr(f.Type)
addr := s.constOffPtrSP(pt, argStart+f.Offset)
if !canSSAType(f.Type) {
s.move(f.Type, addr, argAddrVal)
} else {
argVal := s.load(f.Type, argAddrVal)
s.storeType(f.Type, addr, argVal, 0, false)
}
}
// 调用
var call *ssa.Value
...
call = s.newValue1A(ssa.OpStaticCall, types.TypeMem, fn.Sym.Linksym(), s.mem())
call.AuxInt = stksize
s.vars[&memVar] = call
...
s.endBlock()
s.startBlock(bEnd)
}
}
|
很多 defer 语句都可以在编译期间判断是否被执行,如果函数中的 defer 语句都会在编译期间确定,中间代码生成阶段就会直接调用 cmd/compile/internal/gc.state.openDeferExit 在函数返回前生成判断 deferBits 的代码。
不过当程序遇到运行时才能判断的条件语句时,我们仍然需要由运行时的 runtime.deferreturn 决定是否执行 defer 关键字:
1
2
3
4
5
6
7
8
9
10
11
12
|
func deferreturn(arg0 uintptr) {
gp := getg()
d := gp._defer
sp := getcallersp()
if d.openDefer {
runOpenDeferFrame(gp, d)
gp._defer = d.link
freedefer(d)
return
}
...
}
|
该函数为开放编码做了特殊的优化,运行时会调用 runtime.runOpenDeferFrame 执行活跃的开放编码延迟函数,该函数会执行以下的工作:
- 从 runtime._defer 结构体中读取 deferBits、函数 defer 数量等信息;
- 在循环中依次读取函数的地址和参数信息并通过 deferBits 判断该函数是否需要被执行;
- 调用 runtime.reflectcallSave 调用需要执行的 defer 函数;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
func runOpenDeferFrame(gp *g, d *_defer) bool {
fd := d.fd
...
deferBitsOffset, fd := readvarintUnsafe(fd)
nDefers, fd := readvarintUnsafe(fd)
deferBits := *(*uint8)(unsafe.Pointer(d.varp - uintptr(deferBitsOffset)))
for i := int(nDefers) - 1; i >= 0; i-- {
var argWidth, closureOffset, nArgs uint32 // 读取函数的地址和参数信息
argWidth, fd = readvarintUnsafe(fd)
closureOffset, fd = readvarintUnsafe(fd)
nArgs, fd = readvarintUnsafe(fd)
if deferBits&(1<<i) == 0 {
...
continue
}
closure := *(**funcval)(unsafe.Pointer(d.varp - uintptr(closureOffset)))
d.fn = closure
...
deferBits = deferBits &^ (1 << i)
*(*uint8)(unsafe.Pointer(d.varp - uintptr(deferBitsOffset))) = deferBits
p := d._panic
reflectcallSave(p, unsafe.Pointer(closure), deferArgs, argWidth)
if p != nil && p.aborted {
break
}
d.fn = nil
memclrNoHeapPointers(deferArgs, uintptr(argWidth))
...
}
return done
}
|
从整个过程中我们可以看到,开放编码式 defer 并不是绝对的零成本,尽管编译器能够做到将 延迟调用直接插入返回语句之前,但出于语义的考虑,需要在栈上对参与延迟调用的参数进行一次求值; 同时出于条件语句中可能存在的 defer,还额外需要通过延迟比特来记录一个延迟语句是否在运行时 被设置。 因此,开放编码式 defer 的成本体现在非常少量的指令和位运算来配合在运行时判断 是否存在需要被延迟调用的 defer。
小结
我们在本节前面提到的两个现象在这里也可以解释清楚了:
- 后调用的 defer 函数会先执行:
- 后调用的 defer 函数会被追加到 Goroutine _defer 链表的最前面;
- 运行 runtime._defer 时是从前到后依次执行;
- 函数的参数会被预先计算;
- 调用 runtime.deferproc 函数创建新的延迟调用时就会立刻拷贝函数的参数,函数的参数不会等到真正执行时计算;
我们最后来总结一下 defer 的基本工作原理以及三种 defer 的性能取舍
- 对于开放编码式 defer 而言(1.14):
- 编译器会直接将所需的参数进行存储,并在返回语句的末尾插入被延迟的调用;
- 通过 deferBits 和 cmd/compile/internal/gc.openDeferInfo 存储 defer 关键字的相关信息;
- 编译期间判断 defer 关键字、return 语句的个数确定是否开启开放编码优化;当整个调用中逻辑上会执行的 defer 不超过 15 个(例如七个 defer 作用在两个返回语句)、总 defer 数量不超过 8 个、且没有出现在循环语句中时,会激活使用此类 defer;
- 如果 defer 关键字的执行可以在编译期间确定,会在函数返回前直接插入相应的代码,否则会由运行时的 runtime.deferreturn 处理;
- 此类 defer 的唯一的运行时成本就是存储参与延迟调用的相关信息,运行时性能最好。
- 对于栈上分配的 defer 而言(1.13):
- 当该关键字在函数体中最多执行一次时,编译期间的 cmd/compile/internal/gc.state.call 会将结构体分配到栈上并调用 runtime.deferprocStack;
- 编译器会直接在栈上记录一个 _defer 记录,该记录不涉及内存分配,并将其作为参数,传入被翻译为 deferprocStack 的延迟语句,在延迟调用的位置将_defer 压入 Goroutine 对应的延迟调用链表中;
- 在函数末尾处,通过编译器的配合,在调用被 defer 的函数前,调用 deferreturn,将被延迟的调用出栈并执行;
- 此类 defer 的唯一运行时成本是从 _defer 记录中将参数复制出,以及从延迟调用记录链表出栈的成本,运行时性能其次。
- 对于堆上分配的 defer 而言:
- 编译期将 defer 关键字转换成 runtime.deferproc 并在调用 defer 关键字的函数返回之前插入 runtime.deferreturn;
- 运行时调用 runtime.deferproc 会将一个新的 runtime._defer 结构体追加到当前 Goroutine 的链表头;编译器首先会将延迟语句翻译为一个 deferproc 调用,进而从运行时分配一个用于记录被延迟调用的_defer 记录,并将被延迟的调用的入口地址及其参数复制保存,入栈到 Goroutine 对应的延迟调用链表中;
- 运行时调用 runtime.deferreturn 会从 Goroutine 的链表中取出 runtime._defer 结构并依次执行;在函数末尾处,通过编译器的配合,在调用被 defer 的函数前,调用 deferreturn,从而将_defer 实例归还到资源池,而后通过模拟尾递归的方式来对需要 defer 的函数进行调用。
- 此类 defer 的主要性能问题存在于每个 defer 语句产生记录时的内存分配,记录参数和完成调用时的参数移动时的系统调用,运行时性能最差。
参考
5.3 defer
9.2 延迟语句