channel
hchan
Go 语言的 Channel 在运行时使用 runtime.hchan 结构体表示。我们在 Go 语言中创建新的 Channel 时,实际上创建的都是如下所示的结构:
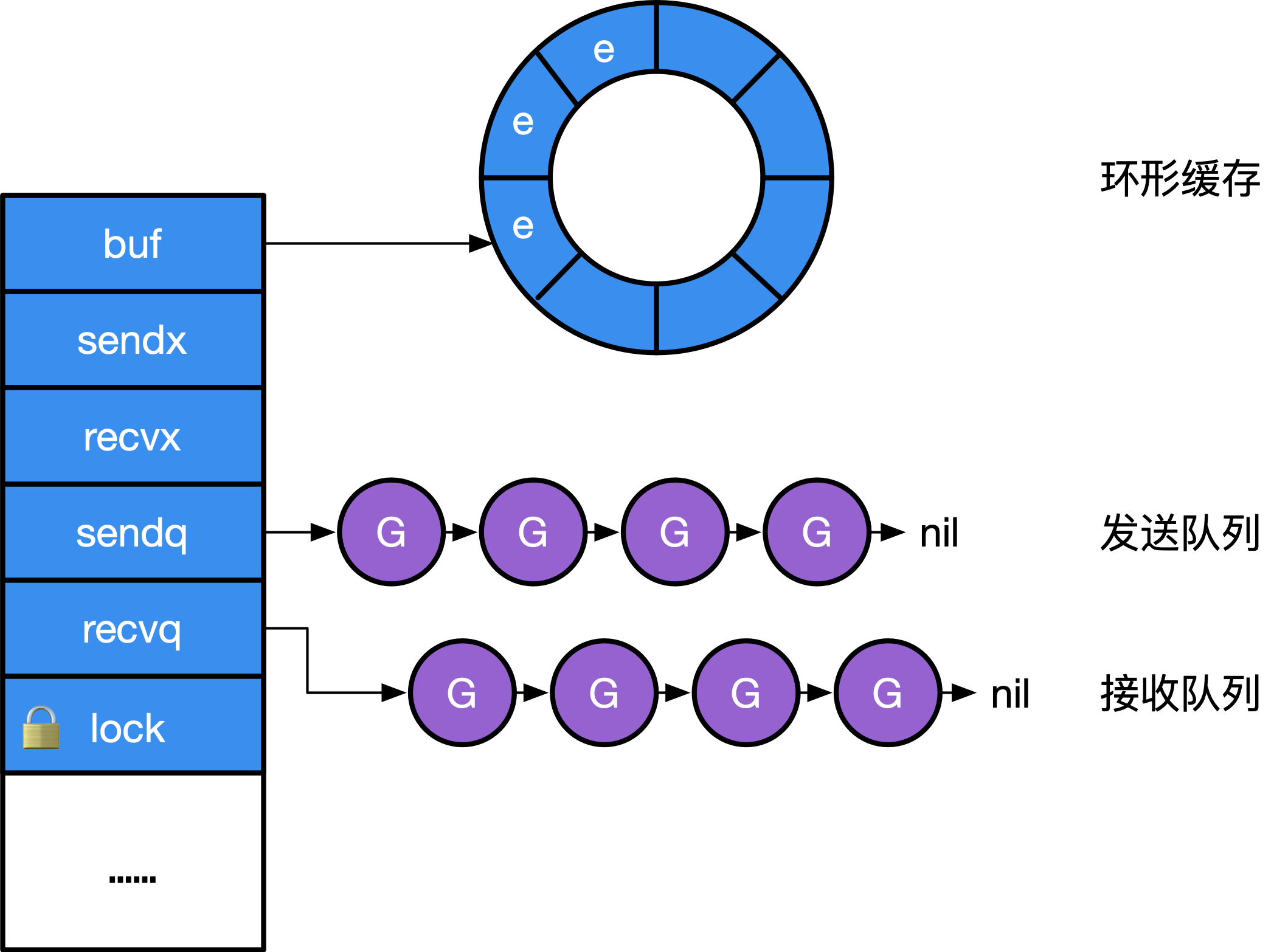
实现 Channel 的结构并不神秘,本质上就是一个 mutex 锁加上一个环状缓存、 一个发送方队列和一个接收方队列:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
type hchan struct {
// 队列中的所有数据数
qcount uint // total data in the queue
// 环形队列的大小
dataqsiz uint // size of the circular queue
// 指向大小为 dataqsiz 的数组
buf unsafe.Pointer // points to an array of dataqsiz elements
// 元素大小
elemsize uint16
// 是否关闭
closed uint32
// 元素类型
elemtype *_type // element type
// Channel 的发送操作处理到的位置
sendx uint // send index
// Channel 的接收操作处理到的位置
recvx uint // receive index
// recv 等待列表,即( <-ch )
recvq waitq // list of recv waiters
// send 等待列表,即( ch<- )
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}
// 等待队列 sudog 双向队列
type waitq struct {
first *sudog
last *sudog
}
func (q *waitq) enqueue(sgp *sudog) {
sgp.next = nil
x := q.last
if x == nil {
sgp.prev = nil
q.first = sgp
q.last = sgp
return
}
sgp.prev = x
x.next = sgp
q.last = sgp
}
func (q *waitq) dequeue() *sudog {
for {
sgp := q.first
if sgp == nil {
return nil
}
y := sgp.next
if y == nil {
q.first = nil
q.last = nil
} else {
y.prev = nil
q.first = y
sgp.next = nil // mark as removed (see dequeueSudog)
}
// if a goroutine was put on this queue because of a
// select, there is a small window between the goroutine
// being woken up by a different case and it grabbing the
// channel locks. Once it has the lock
// it removes itself from the queue, so we won't see it after that.
// We use a flag in the G struct to tell us when someone
// else has won the race to signal this goroutine but the goroutine
// hasn't removed itself from the queue yet.
if sgp.isSelect && !atomic.Cas(&sgp.g.selectDone, 0, 1) {
continue
}
return sgp
}
}
|
makechan
Go 语言中所有 Channel 的创建都会使用 make 关键字。编译器会将 make(chan int, 10) 表达式转换成 OMAKE 类型的节点,并在类型检查阶段将 OMAKE 类型的节点转换成 OMAKECHAN 类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func typecheck1(n *Node, top int) (res*Node) {
switch n.Op {
case OMAKE:
...
switch t.Etype {
case TCHAN:
l = nil
if i < len(args) { // 带缓冲区的异步 Channel
...
n.Left = l
} else { // 不带缓冲区的同步 Channel
n.Left = nodintconst(0)
}
n.Op = OMAKECHAN
}
}
}
|
这一阶段会对传入 make 关键字的缓冲区大小进行检查,如果我们不向 make 传递表示缓冲区大小的参数,那么就会设置一个默认值 0,也就是当前的 Channel 不存在缓冲区。
OMAKECHAN 类型的节点最终都会在 SSA 中间代码生成阶段之前被转换成调用 runtime.makechan 或者 runtime.makechan64 的函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func walkexpr(n *Node, init*Nodes) *Node {
switch n.Op {
case OMAKECHAN:
size := n.Left
fnname := "makechan64"
argtype := types.Types[TINT64]
if size.Type.IsKind(TIDEAL) || maxintval[size.Type.Etype].Cmp(maxintval[TUINT]) <= 0 {
fnname = "makechan"
argtype = types.Types[TINT]
}
n = mkcall1(chanfn(fnname, 1, n.Type), n.Type, init, typename(n.Type), conv(size, argtype))
}
}
|
将一个 make 语句转换为 makechan 调用。 而具体的 makechan 实现的本质是根据需要创建的元素大小, 对 mallocgc 进行封装, 因此,Channel 总是在堆上进行分配,它们会被垃圾回收器进行回收, 这也是为什么 Channel 不一定总是需要调用 close(ch) 进行显式地关闭。
runtime.makechan 和 runtime.makechan64 会根据传入的参数类型和缓冲区大小创建一个新的 Channel 结构,其中后者用于处理缓冲区大小大于 2 的 32 次方的情况,因为这在 Channel 中并不常见,所以我们重点关注 runtime.makechan
Channel 并不严格支持 int64 大小的缓冲,当 make(chan type, n) 中 n 为 int64 类型时, 运行时的实现仅仅只是将其强转为 int,提供了对 int 转型是否成功的检查:
1
2
3
4
5
6
7
8
|
func makechan64(t *chantype, size int64) *hchan {
if int64(int(size)) != size {
panic(plainError("makechan: size out of range"))
}
return makechan(t, int(size))
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// compiler checks this but be safe.
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
// 检查确认 channel 的容量不会溢出
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
// Hchan does not contain pointers interesting for GC when elements stored in buf do not contain pointers.
// buf points into the same allocation, elemtype is persistent.
// SudoG's are referenced from their owning thread so they can't be collected.
// TODO(dvyukov,rlh): Rethink when collector can move allocated objects.
var c *hchan
switch {
case mem == 0:
// 队列或元素大小为零
// Queue or element size is zero.
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// 元素不包含指针
// 在一个调用中分配 hchan 和 buf
// Elements do not contain pointers.
// Allocate hchan and buf in one call.
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// Elements contain pointers.
// 元素包含指针
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
lockInit(&c.lock, lockRankHchan)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.size, "; dataqsiz=", size, "\n")
}
return c
}
|
上述代码根据 Channel 中收发元素的类型和缓冲区的大小初始化 runtime.hchan 和缓冲区:
- 如果当前 Channel 中不存在缓冲区,那么就只会为 runtime.hchan 分配一段内存空间;
- 如果当前 Channel 中存储的类型不是指针类型,会为当前的 Channel 和底层的数组分配一块连续的内存空间;
- 在默认情况下会单独为 runtime.hchan 和缓冲区分配内存;
在函数的最后会统一更新 runtime.hchan 的 elemsize、elemtype 和 dataqsiz 几个字段。
chansend
当我们想要向 Channel 发送数据时,就需要使用 ch <- i 语句,编译器会将它解析成 OSEND 节点并在 cmd/compile/internal/gc.walkexpr 中转换成 runtime.chansend1:
1
2
3
4
5
6
7
8
9
10
|
func walkexpr(n *Node, init*Nodes) *Node {
switch n.Op {
case OSEND:
n1 := n.Right
n1 = assignconv(n1, n.Left.Type.Elem(), "chan send")
n1 = walkexpr(n1, init)
n1 = nod(OADDR, n1, nil)
n = mkcall1(chanfn("chansend1", 2, n.Left.Type), nil, init, n.Left, n1)
}
}
|
runtime.chansend1 只是调用了 runtime.chansend 并传入 Channel 和需要发送的数据。
1
2
3
4
5
|
// entry point for c <- x from compiled code
//go:nosplit
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
|
runtime.chansend 是向 Channel 中发送数据时一定会调用的函数,该函数包含了发送数据的全部逻辑,如果我们在调用时将 block 参数设置成 true,那么表示当前发送操作是阻塞的.
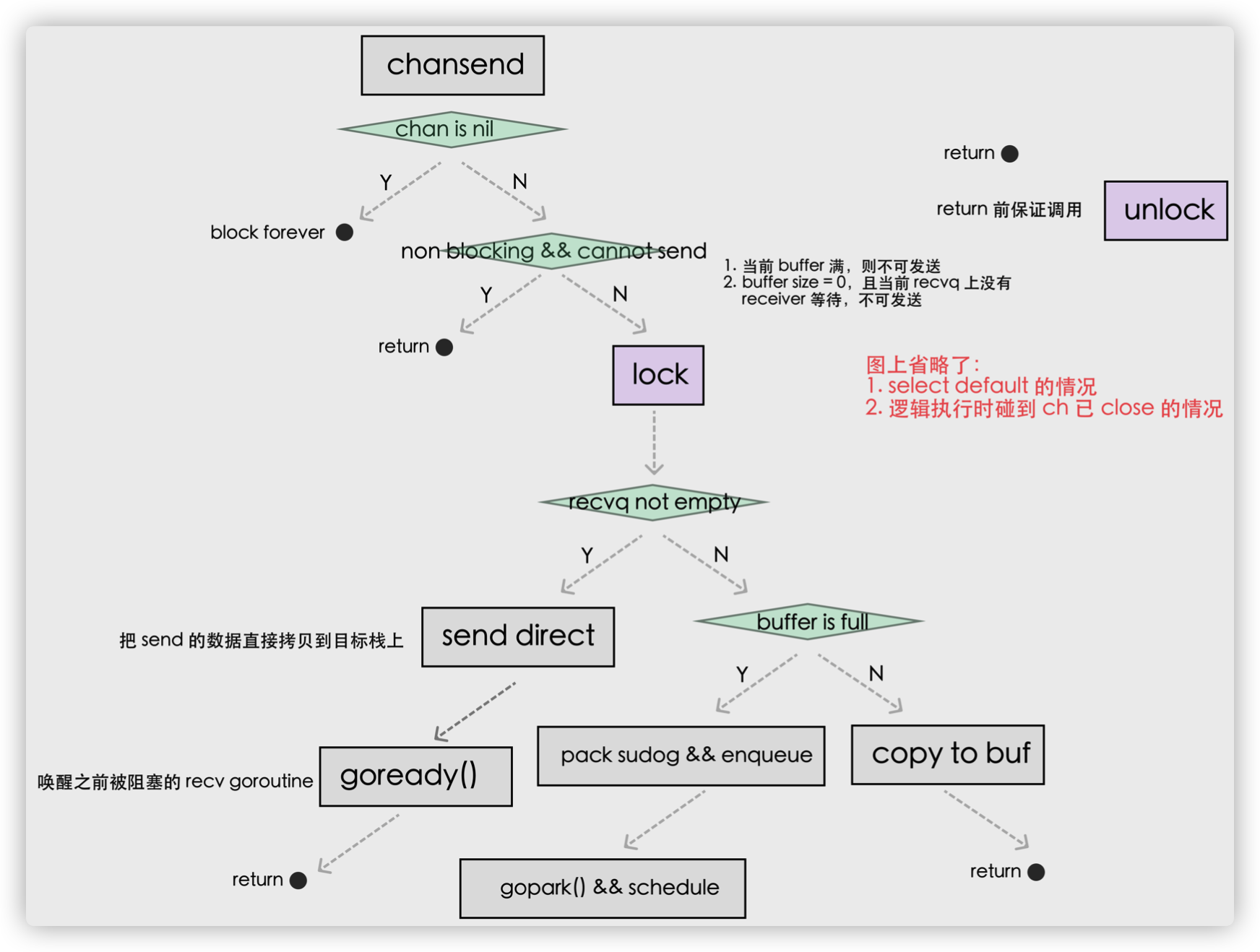
使用 ch <- i 表达式向 Channel 发送数据时遇到的几种情况:
- 如果当前 Channel 的 recvq 上存在已经被阻塞的 Goroutine,那么会直接将数据发送给当前 Goroutine 并将其设置成下一个运行的 Goroutine;
- 如果 Channel 存在缓冲区并且其中还有空闲的容量,我们会直接将数据存储到缓冲区 sendx 所在的位置上;
- 如果不满足上面的两种情况,会创建一个 runtime.sudog 结构并将其加入 Channel 的 sendq 队列中,当前 Goroutine 也会陷入阻塞等待其他的协程从 Channel 接收数据;
发送数据的过程中包含几个会触发 Goroutine 调度的时机:
- 当 Channel 为空时;
- 发送数据时发现 Channel 上存在等待接收数据的 Goroutine,立刻设置处理器的 runnext 属性,但是并不会立刻触发调度;
- 发送数据时并没有找到接收方并且缓冲区已经满了,这时会将自己加入 Channel 的 sendq 队列并调用 runtime.gopark 触发 Goroutine 的调度让出处理器的使用权;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
|
/*
* generic single channel send/recv
* If block is not nil,
* then the protocol will not
* sleep but return if it could
* not complete.
*
* sleep can wake up with g.param == nil
* when a channel involved in the sleep has
* been closed. it is easiest to loop and re-run
* the operation; we'll see that it's now closed.
*/
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// 当向 nil channel 发送数据时,会调用 gopark
// 而 gopark 会将当前的 Goroutine 休眠,从而发生死锁崩溃
if c == nil {
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
if debugChan {
print("chansend: chan=", c, "\n")
}
if raceenabled {
racereadpc(c.raceaddr(), callerpc, funcPC(chansend))
}
// Fast path: check for failed non-blocking operation without acquiring the lock.
//
// After observing that the channel is not closed, we observe that the channel is
// not ready for sending. Each of these observations is a single word-sized read
// (first c.closed and second full()).
// Because a closed channel cannot transition from 'ready for sending' to
// 'not ready for sending', even if the channel is closed between the two observations,
// they imply a moment between the two when the channel was both not yet closed
// and not ready for sending. We behave as if we observed the channel at that moment,
// and report that the send cannot proceed.
//
// It is okay if the reads are reordered here: if we observe that the channel is not
// ready for sending and then observe that it is not closed, that implies that the
// channel wasn't closed during the first observation. However, nothing here
// guarantees forward progress. We rely on the side effects of lock release in
// chanrecv() and closechan() to update this thread's view of c.closed and full().
// 快速路径: 检查不需要加锁时失败的非阻塞操作
// 这里的快速路径是一个优化,它发生在持有 Channel 锁之前。 这一连串检查不需要加锁有以下原因:
// 1. Channel 没有被关闭与 Channel 是否满的检查没有因果关系。换句话说,无论 Channel 是否被关闭,都不能得出 Channel 是否已满;Channel 是否满,也与 Channel 是否关闭无关,从而当发生指令重排时,这个检查也不会出错。
// 2. 当 Channel 已经被关闭、且缓存已满时,发送操作一定失败。
if !block && c.closed == 0 && full(c) {
return false
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
// 在发送数据的逻辑执行之前会先为当前 Channel 加锁,防止多个线程并发修改数据。
lock(&c.lock)
// 持有锁之前我们已经检查了锁的状态,
// 但这个状态可能在持有锁之前、该检查之后发生变化,
// 因此还需要再检查一次 channel 的状态
// 如果 Channel 已经关闭,那么向该 Channel 发送数据时会报 “send on closed channel” 错误并中止程序。
if c.closed != 0 { // 不允许向已经 close 的 channel 发送数据
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
// 如果目标 Channel 没有被关闭并且已经有处于读等待的 Goroutine,那么 runtime.chansend 会从接收队列 recvq 中取出最先陷入等待的 Goroutine 并直接向它发送数据:
// 1. 当存在等待的接收者时,通过 runtime.send 直接将数据发送给阻塞的接收者;
if sg := c.recvq.dequeue(); sg != nil {
// Found a waiting receiver. We pass the value we want to send
// directly to the receiver, bypassing the channel buffer (if any).
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
// 如果创建的 Channel 包含缓冲区并且 Channel 中的数据没有装满,会执行下面这段代码:
// 2. 当缓冲区存在空余空间时,将发送的数据写入 Channel 的缓冲区;
if c.qcount < c.dataqsiz {
// Space is available in the channel buffer. Enqueue the element to send.
// 使用 runtime.chanbuf 计算出下一个可以存储数据的位置,
// 有剩余空间,存入 c.buf
qp := chanbuf(c, c.sendx)
if raceenabled {
racenotify(c, c.sendx, nil)
}
// 通过 runtime.typedmemmove 将发送的数据拷贝到缓冲区中
// 将要发送的数据拷贝到 buf 中
typedmemmove(c.elemtype, qp, ep)
// 向 Channel 发送的数据会存储在 Channel 的 sendx 索引所在的位置并将 sendx 索引加一
c.sendx++
// 因为这里的 buf 是一个循环数组,所以当 sendx 等于 dataqsiz 时会重新回到数组开始的位置。
if c.sendx == c.dataqsiz { // 如果 sendx 索引越界则设为 0
c.sendx = 0
}
// 完成存入,记录增加的数据,解锁
c.qcount++
unlock(&c.lock)
return true
}
// 当 Channel 没有接收者能够处理数据时,向 Channel 发送数据会被下游阻塞,当然使用 select 关键字可以向 Channel 非阻塞地发送消息。
if !block {
unlock(&c.lock)
return false
}
//3. 当不存在缓冲区或者缓冲区已满时,等待其他 Goroutine 从 Channel 接收数据;
// Block on the channel. Some receiver will complete our operation for us.
// 调用 runtime.getg 获取发送数据使用的 Goroutine;
gp := getg()
// 执行 runtime.acquireSudog 获取 runtime.sudog 结构并设置这一次阻塞发送的相关信息,例如发送的 Channel、是否在 select 中和待发送数据的内存地址等;
mysg := acquireSudog()
// 将刚刚创建并初始化的 runtime.sudog 加入发送等待队列,并设置到当前 Goroutine 的 waiting 上,表示 Goroutine 正在等待该 sudog 准备就绪;
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
c.sendq.enqueue(mysg)
// Signal to anyone trying to shrink our stack that we're about
// to park on a channel. The window between when this G's status
// changes and when we set gp.activeStackChans is not safe for
// stack shrinking.
atomic.Store8(&gp.parkingOnChan, 1)
// 调用 runtime.gopark 将当前的 Goroutine 陷入沉睡等待唤醒;
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2) // 将当前的 g 从调度队列移出
// Ensure the value being sent is kept alive until the
// receiver copies it out. The sudog has a pointer to the
// stack object, but sudogs aren't considered as roots of the
// stack tracer.
KeepAlive(ep)
// someone woke us up.
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
// 被调度器唤醒后会执行一些收尾工作,将一些属性置零并且释放 runtime.sudog 结构体;
// 因为调度器在停止当前 g 的时候会记录运行现场,当恢复阻塞的发送操作时候,会从此处继续开始执行
gp.waiting = nil
gp.activeStackChans = false
closed := !mysg.success
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
mysg.c = nil // 取消与之前阻塞的 channel 的关联
releaseSudog(mysg) // 从 sudog 中移除
if closed {
// 正常唤醒状态,Goroutine 应该包含需要传递的参数,但如果没有唤醒时的参数,且 channel 没有被关闭,则为虚假唤醒
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
panic(plainError("send on closed channel"))
}
// 最后返回 true 表示这次我们已经成功向 Channel 发送了数据。
return true
}
func chanparkcommit(gp *g, chanLock unsafe.Pointer) bool {
// 具有未解锁的指向 gp 栈的 sudog。栈的复制必须锁住那些 sudog 的 channel
// There are unlocked sudogs that point into gp's stack. Stack
// copying must lock the channels of those sudogs.
// Set activeStackChans here instead of before we try parking
// because we could self-deadlock in stack growth on the
// channel lock.
gp.activeStackChans = true
// Mark that it's safe for stack shrinking to occur now,
// because any thread acquiring this G's stack for shrinking
// is guaranteed to observe activeStackChans after this store.
atomic.Store8(&gp.parkingOnChan, 0)
// Make sure we unlock after setting activeStackChans and
// unsetting parkingOnChan. The moment we unlock chanLock
// we risk gp getting readied by a channel operation and
// so gp could continue running before everything before
// the unlock is visible (even to gp itself).
unlock((*mutex)(chanLock))
return true
}
// chanbuf(c, i) is pointer to the i'th slot in the buffer.
func chanbuf(c *hchan, i uint) unsafe.Pointer {
return add(c.buf, uintptr(i)*uintptr(c.elemsize))
}
// typedmemmove copies a value of type t to dst from src.
// Must be nosplit, see #16026.
//
// TODO: Perfect for go:nosplitrec since we can't have a safe point
// anywhere in the bulk barrier or memmove.
//
//go:nosplit
func typedmemmove(typ *_type, dst, src unsafe.Pointer) {
if dst == src {
return
}
if writeBarrier.needed && typ.ptrdata != 0 {
bulkBarrierPreWrite(uintptr(dst), uintptr(src), typ.ptrdata)
}
// There's a race here: if some other goroutine can write to
// src, it may change some pointer in src after we've
// performed the write barrier but before we perform the
// memory copy. This safe because the write performed by that
// other goroutine must also be accompanied by a write
// barrier, so at worst we've unnecessarily greyed the old
// pointer that was in src.
memmove(dst, src, typ.size)
if writeBarrier.cgo {
cgoCheckMemmove(typ, dst, src, 0, typ.size)
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// full reports whether a send on c would block (that is, the channel is full).
// It uses a single word-sized read of mutable state, so although
// the answer is instantaneously true, the correct answer may have changed
// by the time the calling function receives the return value.
func full(c *hchan) bool {
// c.dataqsiz is immutable (never written after the channel is created)
// so it is safe to read at any time during channel operation.
if c.dataqsiz == 0 {
// Assumes that a pointer read is relaxed-atomic.
return c.recvq.first == nil
}
// Assumes that a uint read is relaxed-atomic.
return c.qcount == c.dataqsiz
}
|
send
直接发送数据时会调用 runtime.send,该函数的执行可以分成两个部分:
- 调用 runtime.sendDirect 将发送的数据直接拷贝到 x = <-c 表达式中变量 x 所在的内存地址上;
- 调用 runtime.goready 将等待接收数据的 Goroutine 标记成可运行状态 Grunnable 并把该 Goroutine 放到发送方所在的处理器的 runnext 上等待执行,该处理器在下一次调度时会立刻唤醒数据的接收方;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
// send processes a send operation on an empty channel c.
// The value ep sent by the sender is copied to the receiver sg.
// The receiver is then woken up to go on its merry way.
// Channel c must be empty and locked. send unlocks c with unlockf.
// sg must already be dequeued from c.
// ep must be non-nil and point to the heap or the caller's stack.
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if raceenabled {
if c.dataqsiz == 0 {
racesync(c, sg)
} else {
// Pretend we go through the buffer, even though
// we copy directly. Note that we need to increment
// the head/tail locations only when raceenabled.
racenotify(c, c.recvx, nil)
racenotify(c, c.recvx, sg)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
}
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
// Sends and receives on unbuffered or empty-buffered channels are the
// only operations where one running goroutine writes to the stack of
// another running goroutine. The GC assumes that stack writes only
// happen when the goroutine is running and are only done by that
// goroutine. Using a write barrier is sufficient to make up for
// violating that assumption, but the write barrier has to work.
// typedmemmove will call bulkBarrierPreWrite, but the target bytes
// are not in the heap, so that will not help. We arrange to call
// memmove and typeBitsBulkBarrier instead.
func sendDirect(t *_type, sg *sudog, src unsafe.Pointer) {
// src is on our stack, dst is a slot on another stack.
// Once we read sg.elem out of sg, it will no longer
// be updated if the destination's stack gets copied (shrunk).
// So make sure that no preemption points can happen between read & use.
dst := sg.elem
// 为了确保发送的数据能够被立刻观察到,需要写屏障支持,执行写屏障,保证代码正确性
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size)
// No need for cgo write barrier checks because dst is always
// Go memory.
// 直接写入接收方的执行栈
memmove(dst, src, t.size)
}
|
send 操作其实是一种优化。原因在于,已经处于等待状态的 Goroutine 是没有被执行的, 因此用户态代码不会与当前所发生数据发生任何竞争。我们也更没有必要冗余的将数据写入到缓存, 再让接收方从缓存中进行读取。因此我们可以看到, sendDirect 的调用, 本质上是将数据直接写入接收方的执行栈。
chanrecv
我们接下来继续介绍 Channel 操作的另一方:接收数据。Go 语言中可以使用两种不同的方式去接收 Channel 中的数据:
这两种不同的方法经过编译器的处理都会变成 ORECV 类型的节点,后者会在类型检查阶段被转换成 OAS2RECV 类型。数据的接收操作遵循以下的路线图:
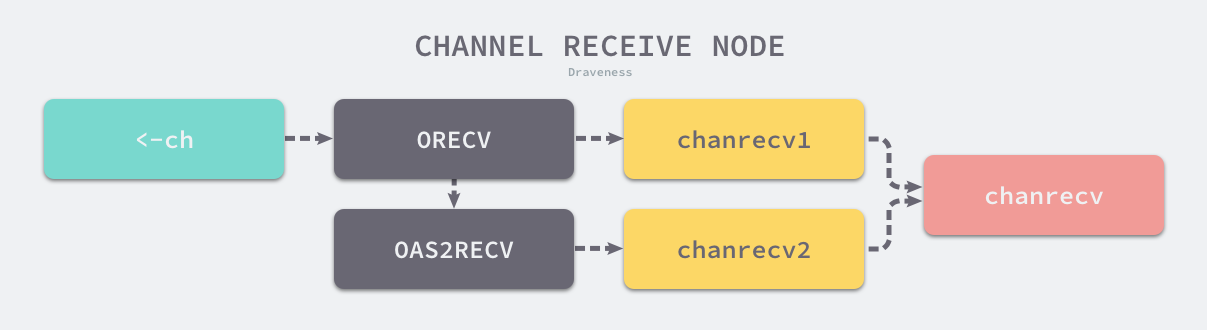
虽然不同的接收方式会被转换成 runtime.chanrecv1 和 runtime.chanrecv2 两种不同函数的调用,但是这两个函数最终还是会调用 runtime.chanrecv。
1
2
3
4
5
6
7
8
9
10
11
|
// entry points for <- c from compiled code
//go:nosplit
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
//go:nosplit
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}
|
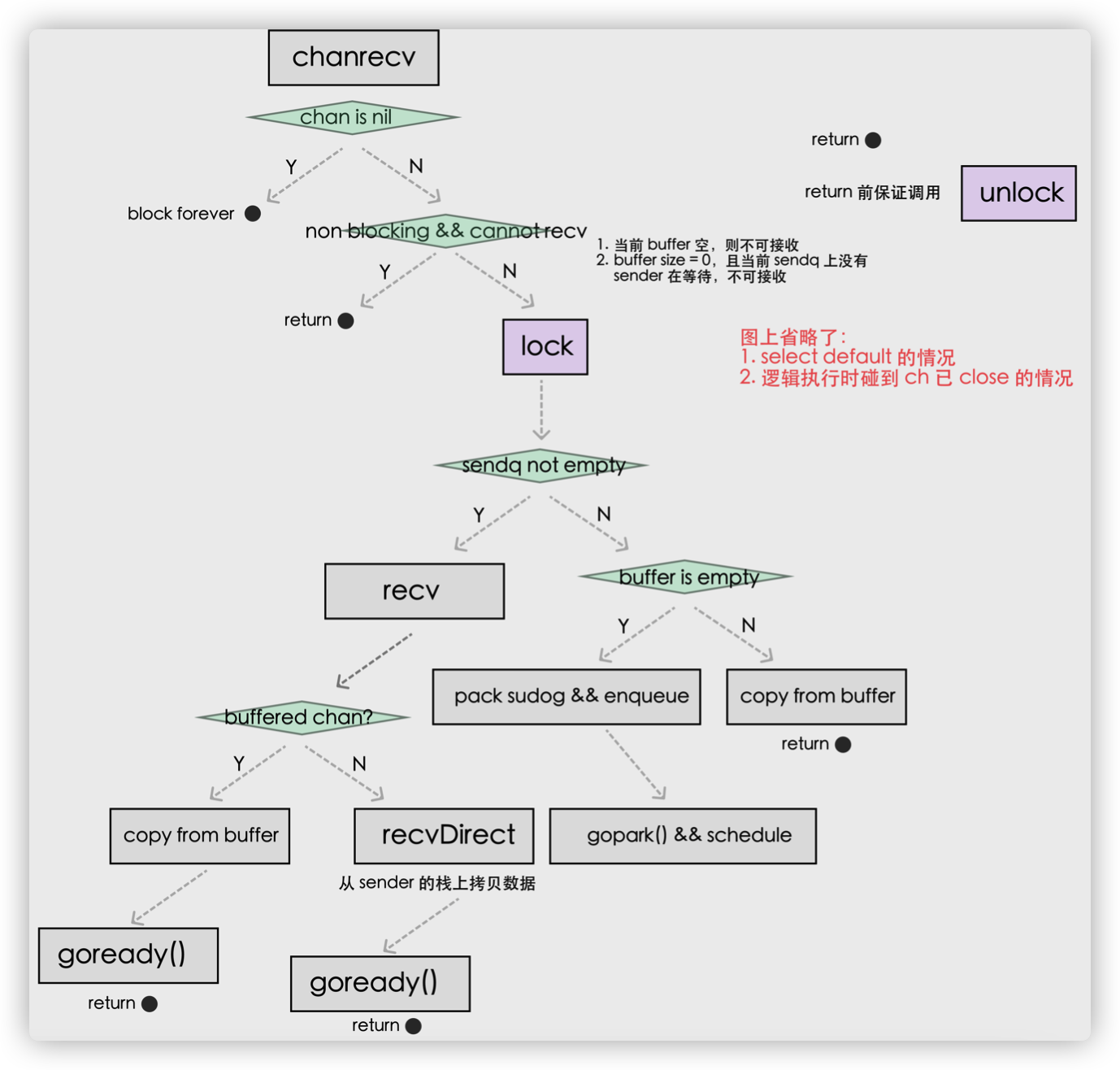
我们梳理一下从 Channel 中接收数据时可能会发生的五种情况:
- 如果 Channel 为空,那么会直接调用 runtime.gopark 挂起当前 Goroutine;
- 如果 Channel 已经关闭并且缓冲区没有任何数据,runtime.chanrecv 会直接返回;
- 如果 Channel 的 sendq 队列中存在挂起的 Goroutine,会将 recvx 索引所在的数据拷贝到接收变量所在的内存空间上并将 sendq 队列中 Goroutine 的数据拷贝到缓冲区;
- 如果 Channel 的缓冲区中包含数据,那么直接读取 recvx 索引对应的数据;
- 在默认情况下会挂起当前的 Goroutine,将 runtime.sudog 结构加入 recvq 队列并陷入休眠等待调度器的唤醒;
我们总结一下从 Channel 接收数据时,会触发 Goroutine 调度的两个时机:
- 当 Channel 为空时;
- 当缓冲区中不存在数据并且也不存在数据的发送者时;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
|
// chanrecv receives on channel c and writes the received data to ep.
// ep may be nil, in which case received data is ignored.
// If block == false and no elements are available, returns (false, false).
// Otherwise, if c is closed, zeros *ep and returns (true, false).
// Otherwise, fills in *ep with an element and returns (true, true).
// A non-nil ep must point to the heap or the caller's stack.
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// raceenabled: don't need to check ep, as it is always on the stack
// or is new memory allocated by reflect.
if debugChan {
print("chanrecv: chan=", c, "\n")
}
// 当我们从一个空 Channel 接收数据时会直接调用 runtime.gopark 让出处理器的使用权。
// nil channel,同 send,会导致两个 Goroutine 的死锁
if c == nil {
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// 快速路径: 在不需要锁的情况下检查失败的非阻塞操作
//
// 注意到 channel 不能由已关闭转换为未关闭,则
// 失败的条件是:1. 无 buf 时发送队列为空 2. 有 buf 时,buf 为空
// 此处的 c.closed 必须在条件判断之后进行验证,
// 因为指令重排后,如果先判断 c.closed,得出 channel 未关闭,无法判断失败条件中
// channel 是已关闭还是未关闭(从而需要 atomic 操作)
// Fast path: check for failed non-blocking operation without acquiring the lock.
if !block && empty(c) {
// After observing that the channel is not ready for receiving, we observe whether the
// channel is closed.
//
// Reordering of these checks could lead to incorrect behavior when racing with a close.
// For example, if the channel was open and not empty, was closed, and then drained,
// reordered reads could incorrectly indicate "open and empty". To prevent reordering,
// we use atomic loads for both checks, and rely on emptying and closing to happen in
// separate critical sections under the same lock. This assumption fails when closing
// an unbuffered channel with a blocked send, but that is an error condition anyway.
if atomic.Load(&c.closed) == 0 {
// Because a channel cannot be reopened, the later observation of the channel
// being not closed implies that it was also not closed at the moment of the
// first observation. We behave as if we observed the channel at that moment
// and report that the receive cannot proceed.
return
}
// The channel is irreversibly closed. Re-check whether the channel has any pending data
// to receive, which could have arrived between the empty and closed checks above.
// Sequential consistency is also required here, when racing with such a send.
if empty(c) {
// The channel is irreversibly closed and empty.
if raceenabled {
raceacquire(c.raceaddr())
}
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
lock(&c.lock)
// 如果当前 Channel 已经被关闭并且缓冲区中不存在任何数据,那么会清除 ep 指针中的数据并立刻返回。
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
// 当存在等待的发送者时,通过 runtime.recv 从阻塞的发送者或者缓冲区中获取数据
// 当 Channel 的 sendq 队列中包含处于等待状态的 Goroutine 时,该函数会取出队列头等待的 Goroutine,处理的逻辑和发送时相差无几,只是发送数据时调用的是 runtime.send 函数,而接收数据时使用 runtime.recv:
if sg := c.sendq.dequeue(); sg != nil {
// Found a waiting sender. If buffer is size 0, receive value
// directly from sender. Otherwise, receive from head of queue
// and add sender's value to the tail of the queue (both map to
// the same buffer slot because the queue is full).
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
// 当 Channel 的缓冲区中已经包含数据时,从 Channel 中接收数据会直接从缓冲区中 recvx 的索引位置中取出数据进行处理:
if c.qcount > 0 {
// Receive directly from queue
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
}
// 如果接收数据的内存地址不为空,那么会使用 runtime.typedmemmove 将缓冲区中的数据拷贝到内存中、清除队列中的数据并完成收尾工作。
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
// 收尾工作包括递增 recvx,一旦发现索引超过了 Channel 的容量时,会将它归零重置循环队列的索引;除此之外,该函数还会减少 qcount 计数器并释放持有 Channel 的锁。
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
return true, true
}
if !block {
unlock(&c.lock)
return false, false
}
// 当 Channel 的发送队列中不存在等待的 Goroutine 并且缓冲区中也不存在任何数据时,从管道中接收数据的操作会变成阻塞的,然而不是所有的接收操作都是阻塞的,与 select 语句结合使用时就可能会使用到非阻塞的接收操作:
// no sender available: block on this channel.
// 在正常的接收场景中,我们会使用 runtime.sudog 将当前 Goroutine 包装成一个处于等待状态的 Goroutine 并将其加入到接收队列中。
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg)
// Signal to anyone trying to shrink our stack that we're about
// to park on a channel. The window between when this G's status
// changes and when we set gp.activeStackChans is not safe for
// stack shrinking.
// 完成入队之后,调用 runtime.gopark 立刻触发 Goroutine 的调度,让出处理器的使用权并等待调度器的调度。
atomic.Store8(&gp.parkingOnChan, 1)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
// someone woke us up
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
success := mysg.success
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true, success
}
// empty reports whether a read from c would block (that is, the channel is
// empty). It uses a single atomic read of mutable state.
func empty(c *hchan) bool {
// c.dataqsiz is immutable.
if c.dataqsiz == 0 {
return atomic.Loadp(unsafe.Pointer(&c.sendq.first)) == nil
}
return atomic.Loaduint(&c.qcount) == 0
}
|
recv
接收数据同样包含直接往接收方的执行栈中拷贝要发送的数据,但这种情况当且仅当缓存大小为0时(即无缓冲 Channel)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
// recv processes a receive operation on a full channel c.
// There are 2 parts:
// 1) The value sent by the sender sg is put into the channel
// and the sender is woken up to go on its merry way.
// 2) The value received by the receiver (the current G) is
// written to ep.
// For synchronous channels, both values are the same.
// For asynchronous channels, the receiver gets its data from
// the channel buffer and the sender's data is put in the
// channel buffer.
// Channel c must be full and locked. recv unlocks c with unlockf.
// sg must already be dequeued from c.
// A non-nil ep must point to the heap or the caller's stack.
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// 如果 Channel 不存在缓冲区
if c.dataqsiz == 0 {
if raceenabled {
racesync(c, sg)
}
if ep != nil {
// 直接从对方的栈进行拷贝
// 调用 runtime.recvDirect 将 Channel 发送队列中 Goroutine 存储的 elem 数据拷贝到目标内存地址中;
// copy data from sender
recvDirect(c.elemtype, sg, ep)
}
} else {
// 如果 Channel 存在缓冲区,发送队列头的 runtime.sudog 中的元素会替换接收索引 recvx 所在位置的元素,原有的元素会被拷贝到接收数据的变量对应的内存空间上,保证channel的先进先出.
// Queue is full. Take the item at the
// head of the queue. Make the sender enqueue
// its item at the tail of the queue. Since the
// queue is full, those are both the same slot.
// 将队列中的数据拷贝到接收方的内存地址;
// 从缓存队列拷贝
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
racenotify(c, c.recvx, sg)
}
// copy data from queue to receiver
// 从队列拷贝数据到接收方
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// copy data from sender to queue
// 从发送方拷贝数据到队列
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
// 将发送队列头的数据拷贝到缓冲区中
sg.elem = nil
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
// 无论发生哪种情况,运行时都会调用 runtime.goready 将当前处理器的 runnext 设置成发送数据的 Goroutine,在调度器下一次调度时将阻塞的发送方唤醒。
goready(gp, skip+1)
}
// chanbuf(c, i) is pointer to the i'th slot in the buffer.
func chanbuf(c *hchan, i uint) unsafe.Pointer {
return add(c.buf, uintptr(i)*uintptr(c.elemsize))
}
|
1
2
3
4
5
6
7
8
|
func recvDirect(t *_type, sg *sudog, dst unsafe.Pointer) {
// dst is on our stack or the heap, src is on another stack.
// The channel is locked, so src will not move during this
// operation.
src := sg.elem
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size)
memmove(dst, src, t.size)
}
|
到目前为止我们终于明白了为什么无缓冲 Channel 而言 v <- ch happens before ch <- v 了, 因为无缓冲 Channel 的接收方会先从发送方栈拷贝数据后,发送方才会被放回调度队列中,等待重新调度。
closechan
编译器会将用于关闭管道的 close 关键字转换成 OCLOSE 节点以及 runtime.closechan 函数。
具体的实现中,首先对 Channel 上锁,而后依次将阻塞在 Channel 的 g 添加到一个 gList 中,当所有的 g 均从 Channel 上移除时,可释放锁,并唤醒 gList 中的所有接收方和发送方:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
func closechan(c *hchan) {
// 当 Channel 是一个空指针或者已经被关闭时,Go 语言运行时都会直接崩溃并抛出异常:
if c == nil {
panic(plainError("close of nil channel"))
}
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
if raceenabled {
callerpc := getcallerpc()
racewritepc(c.raceaddr(), callerpc, funcPC(closechan))
racerelease(c.raceaddr())
}
// 将 recvq 和 sendq 两个队列中的数据加入到 Goroutine 列表 gList 中,与此同时该函数会清除所有 runtime.sudog 上未被处理的元素:
c.closed = 1
var glist gList
// release all readers
// 释放所有的接收方
for {
sg := c.recvq.dequeue()
if sg == nil {
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem) // 清零
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
// release all writers (they will panic)
// 释放所有的发送方
for {
sg := c.sendq.dequeue()
if sg == nil { // 队列已空
break
}
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
// 释放 channel 的锁
unlock(&c.lock)
// Ready all Gs now that we've dropped the channel lock.
// 最后会为所有被阻塞的 Goroutine 调用 runtime.goready 触发调度。
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}
|
当 Channel 关闭时,我们必须让所有阻塞的接收方重新被调度,让所有的发送方也重新被调度,这时候 的实现先将 Goroutine 统一添加到一个列表中(需要锁),然后逐个地进行复始(不需要锁)。
select
select 是操作系统中的系统调用,我们经常会使用 select、poll 和 epoll 等函数构建 I/O 多路复用模型提升程序的性能。Go 语言的 select 与操作系统中的 select 比较相似,本节会介绍 Go 语言 select 关键字常见的现象、数据结构以及实现原理。
C 语言的 select 系统调用可以同时监听多个文件描述符的可读或者可写的状态,Go 语言中的 select 也能够让 Goroutine 同时等待多个 Channel 可读或者可写,在多个文件或者 Channel状态改变之前,select 会一直阻塞当前线程或者 Goroutine。
select 是与 switch 相似的控制结构,与 switch 不同的是,select 中虽然也有多个 case,但是这些 case 中的表达式必须都是 Channel 的收发操作。下面的代码就展示了一个包含 Channel 收发操作的 select 结构:
1
2
3
4
5
6
7
8
9
10
11
12
|
func fibonacci(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}
|
上述控制结构会等待 c <- x 或者 <-quit 两个表达式中任意一个返回。无论哪一个表达式返回都会立刻执行 case 中的代码,当 select 中的两个 case 同时被触发时,会随机执行其中的一个。
现象
当我们在 Go 语言中使用 select 控制结构时,会遇到两个有趣的现象:
- select 能在 Channel 上进行非阻塞的收发操作;
- select 在遇到多个 Channel 同时响应时,会随机执行一种情况;
这两个现象是学习 select 时经常会遇到的,我们来深入了解具体场景并分析这两个现象背后的设计原理。
非阻塞的收发
在通常情况下,select 语句会阻塞当前 Goroutine 并等待多个 Channel 中的一个达到可以收发的状态。但是如果 select 控制结构中包含 default 语句,那么这个 select 语句在执行时会遇到以下两种情况:
- 当存在可以收发的 Channel 时,直接处理该 Channel 对应的 case;
- 当不存在可以收发的 Channel 时,执行 default 中的语句;
当我们运行下面的代码时就不会阻塞当前的 Goroutine,它会直接执行 default 中的代码。
1
2
3
4
5
6
7
8
9
10
|
func main() {
ch := make(chan int)
select {
case i := <-ch:
println(i)
default:
println("default")
}
}
|
1
2
|
$ go run main.go
default
|
只要我们稍微想一下,就会发现 Go 语言设计的这个现象很合理。select 的作用是同时监听多个 case 是否可以执行,如果多个 Channel 都不能执行,那么运行 default 也是理所当然的。
非阻塞的 Channel 发送和接收操作还是很有必要的,在很多场景下我们不希望 Channel 操作阻塞当前 Goroutine,只是想看看 Channel 的可读或者可写状态,如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
errCh := make(chan error, len(tasks))
wg := sync.WaitGroup{}
wg.Add(len(tasks))
for i := range tasks {
go func() {
defer wg.Done()
if err := tasks[i].Run(); err != nil {
errCh <- err
}
}()
}
wg.Wait()
select {
case err := <-errCh:
return err
default:
return nil
}
|
在上面这段代码中,我们不关心到底多少个任务执行失败了,只关心是否存在返回错误的任务,最后的 select 语句能很好地完成这个任务。
随机执行
另一个使用 select 遇到的情况是同时有多个 case 就绪时,select 会选择哪个 case 执行的问题,我们通过下面的代码可以简单了解一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func main() {
ch := make(chan int)
go func() {
for range time.Tick(1 * time.Second) {
ch <- 0
}
}()
for {
select {
case <-ch:
println("case1")
case <-ch:
println("case2")
}
}
}
|
1
2
3
4
5
|
$ go run main.go
case1
case2
case1
...
|
从上述代码输出的结果中我们可以看到,select 在遇到多个 <-ch 同时满足可读或者可写条件时会随机选择一个 case 执行其中的代码。
这个设计是在十多年前被 select 提交5引入并一直保留到现在的,虽然中间经历过一些修改6,但是语义一直都没有改变。在上面的代码中,两个 case 都是同时满足执行条件的,如果我们按照顺序依次判断,那么后面的条件永远都会得不到执行,而随机的引入就是为了避免饥饿问题的发生。
数据结构
select 在 Go 语言的源代码中不存在对应的结构体,但是我们使用 runtime.scase 结构体表示 select 控制结构中的 case:
1
2
3
4
|
type scase struct {
c *hchan // chan
elem unsafe.Pointer // data element
}
|
因为非默认的 case 中都与 Channel 的发送和接收有关,所以 runtime.scase 结构体中也包含一个 runtime.hchan 类型的字段存储 case 中使用的 Channel。
实现原理
select 语句在编译期间会被转换成 OSELECT 节点。每个 OSELECT 节点都会持有一组 OCASE 节点,如果 OCASE 的执行条件是空,那就意味着这是一个 default 节点。
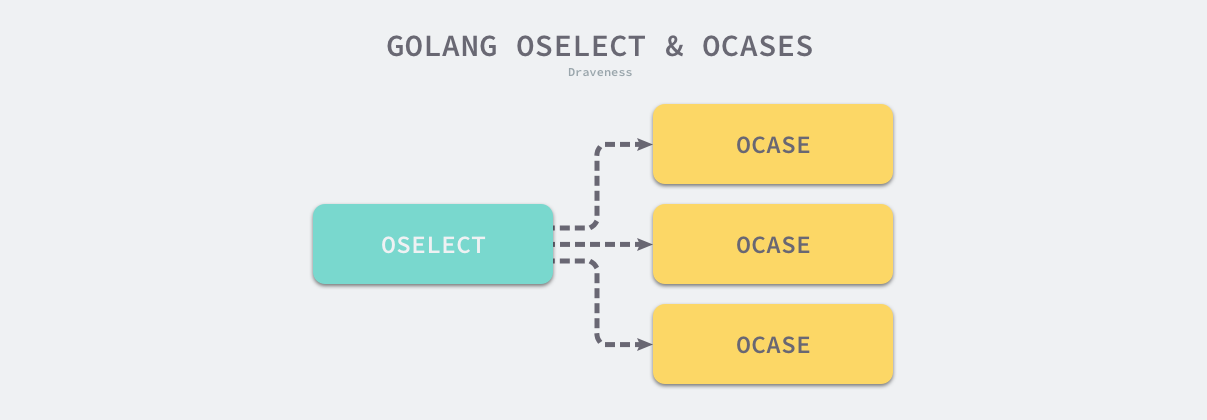
上图展示的就是 select 语句在编译期间的结构,每一个 OCASE 既包含执行条件也包含满足条件后执行的代码。
编译器在中间代码生成期间会根据 select 中 case 的不同对控制语句进行优化,这一过程都发生在 cmd/compile/internal/gc.walkselectcases 函数中,我们在这里会分四种情况介绍处理的过程和结果:
- select 不存在任何的 case;
- select 只存在一个 case;
- select 存在两个 case,其中一个 case 是 default;
- select 存在多个 case;
首先在编译期间,Go 语言会对 select 语句进行优化,它会根据 select 中 case 的不同选择不同的优化路径:
- 空的 select 语句会被转换成调用 runtime.block 直接挂起当前 Goroutine;
- 如果 select 语句中只包含一个 case,编译器会将其转换成
if ch == nil { block }; n; 表达式;
- 首先判断操作的 Channel 是不是空的;
- 然后执行 case 结构中的内容;
- 如果 select 语句中只包含两个 case 并且其中一个是 default,那么会使用 runtime.selectnbrecv 和 runtime.selectnbsend 非阻塞地执行收发操作;
- 在默认情况下会通过 runtime.selectgo 获取执行 case 的索引,并通过多个 if 语句执行对应 case 中的代码;
select 不存在任何的 case
首先介绍的是最简单的情况,也就是当 select 结构中不包含任何 case。我们截取 cmd/compile/internal/gc.walkselectcases 函数的前几行代码:
1
2
3
4
5
6
7
8
|
func walkselectcases(cases *Nodes) []*Node {
n := cases.Len()
if n == 0 {
return []*Node{mkcall("block", nil, nil)}
}
...
}
|
这段代码很简单并且容易理解,它直接将类似 select {} 的语句转换成调用 runtime.block 函数:
1
2
3
|
func block() {
gopark(nil, nil, waitReasonSelectNoCases, traceEvGoStop, 1) // forever
}
|
runtime.block 的实现非常简单,它会调用 runtime.gopark 让出当前 Goroutine 对处理器的使用权并传入等待原因 waitReasonSelectNoCases。
简单总结一下,空的 select 语句会直接阻塞当前 Goroutine,导致 Goroutine 进入无法被唤醒的永久休眠状态。
select 只存在一个 case
如果当前的 select 条件只包含一个 case,那么编译器会将 select 改写成 if 条件语句。下面对比了改写前后的代码:
1
2
3
4
5
6
7
8
9
10
11
12
|
// 改写前
select {
case v, ok <-ch: // case ch <- v
...
}
// 改写后
if ch == nil {
block()
}
v, ok := <-ch // case ch <- v
...
|
1
2
3
|
func block() {
gopark(nil, nil, waitReasonSelectNoCases, traceEvGoStop, 1) // forever
}
|
cmd/compile/internal/gc.walkselectcases 在处理单操作 select 语句时,会根据 Channel 的收发情况生成不同的语句。当 case 中的 Channel 是空指针时,会直接挂起当前 Goroutine 并陷入永久休眠。
所以下面的代码会直接panic:
1
2
3
4
5
6
7
8
9
10
11
|
package main
func main() {
var ch chan int
x := 1
select {
case ch <- x:
println("send success") // 如果初始化为有缓存 channel,则会发送成功
}
return
}
|
只有一个分支的情况下,select 与 if 是没有区别的,这种优化消除了只有一个分支情况下调用 selectgo 的性能开销
select 存在两个 case,其中一个 case 是 default
当 select 中仅包含两个 case,并且其中一个是 default 时,Go 语言的编译器就会认为这是一次非阻塞的收发操作。cmd/compile/internal/gc.walkselectcases 会对这种情况单独处理。不过在正式优化之前,该函数会将 case 中的所有 Channel 都转换成指向 Channel 的地址,我们会分别介绍非阻塞发送和非阻塞接收时,编译器进行的不同优化。
发送
首先是 Channel 的发送过程,当 case 中表达式的类型是 OSEND 时,编译器会使用条件语句和 runtime.selectnbsend 函数改写代码:
1
2
3
4
5
6
7
8
9
10
11
12
|
select {
case ch <- i:
...
default:
...
}
if selectnbsend(ch, i) {
...
} else {
...
}
|
这段代码中最重要的就是 runtime.selectnbsend,它为我们提供了向 Channel 非阻塞地发送数据的能力。我们在 Channel 一节介绍了向 Channel 发送数据的 runtime.chansend 函数包含一个 block 参数,该参数会决定这一次的发送是不是阻塞的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// compiler implements
//
// select {
// case c <- v:
// ... foo
// default:
// ... bar
// }
//
// as
//
// if selectnbsend(c, v) {
// ... foo
// } else {
// ... bar
// }
//
func selectnbsend(c *hchan, elem unsafe.Pointer) (selected bool) {
return chansend(c, elem, false, getcallerpc())
}
|
注意,这时 chansend 的第三个参数为 false,这与前面的普通 Channel 发送操作不同, 说明这时 Select 的操作是非阻塞的。
由于我们向 runtime.chansend 函数传入了非阻塞,所以在不存在接收方或者缓冲区空间不足时,当前 Goroutine 都不会阻塞而是会直接返回。
接收
由于从 Channel 中接收数据可能会返回一个或者两个值,所以接收数据的情况会比发送稍显复杂,不过改写的套路是差不多的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// 改写前
select {
case v <- ch: // case v, ok <- ch:
......
default:
......
}
// 改写后
if selectnbrecv(&v, ch) { // if selectnbrecv2(&v, &ok, ch) {
...
} else {
...
}
|
返回值数量不同会导致使用函数的不同,两个用于非阻塞接收消息的函数 runtime.selectnbrecv 和 runtime.selectnbrecv2 只是对 runtime.chanrecv 返回值的处理稍有不同:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
// compiler implements
//
// select {
// case v = <-c:
// ... foo
// default:
// ... bar
// }
//
// as
//
// if selectnbrecv(&v, c) {
// ... foo
// } else {
// ... bar
// }
//
func selectnbrecv(elem unsafe.Pointer, c *hchan) (selected bool) {
selected, _ = chanrecv(c, elem, false)
return
}
// compiler implements
//
// select {
// case v, ok = <-c:
// ... foo
// default:
// ... bar
// }
//
// as
//
// if c != nil && selectnbrecv2(&v, &ok, c) {
// ... foo
// } else {
// ... bar
// }
//
func selectnbrecv2(elem unsafe.Pointer, received *bool, c *hchan) (selected bool) {
// TODO(khr): just return 2 values from this function, now that it is in Go.
selected, *received = chanrecv(c, elem, false)
return
}
|
因为接收方不需要,所以 runtime.selectnbrecv 会直接忽略返回的布尔值,而 runtime.selectnbrecv2 会将布尔值回传给调用方。与 runtime.chansend 一样,runtime.chanrecv 也提供了一个 block 参数用于控制这次接收是否阻塞。
select 存在多个 case
在默认的情况下,编译器会使用如下的流程处理 select 语句:
- 将所有的 case 转换成包含 Channel 以及类型等信息的 runtime.scase 结构体;
- 调用运行时函数 runtime.selectgo 从多个准备就绪的 Channel 中选择一个可执行的 runtime.scase 结构体;
- 通过 for 循环生成一组 if 语句,在语句中判断自己是不是被选中的 case;
一个包含三个 case 的正常 select 语句其实会被展开成如下所示的逻辑,我们可以看到其中处理的三个部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
selv := [3]scase{}
order := [6]uint16
for i, cas := range cases {
c := scase{}
c.kind = ...
c.elem = ...
c.c = ...
}
chosen, revcOK := selectgo(selv, order, 3)
if chosen == 0 {
...
break
}
if chosen == 1 {
...
break
}
if chosen == 2 {
...
break
}
|
在编译器已经对 select 语句进行优化之后,Go 语言会在运行时执行编译期间展开的 runtime.selectgo 函数,该函数会按照以下的流程执行:
- 随机生成一个遍历的轮询顺序 pollOrder 并根据 Channel 地址生成锁定顺序 lockOrder;
- 根据 pollOrder 遍历所有的 case 查看是否有可以立刻处理的 Channel;
- 如果存在,直接获取 case 对应的索引并返回;
- 如果不存在,创建 runtime.sudog 结构体,将当前 Goroutine 加入到所有相关 Channel 的收发队列,并调用 runtime.gopark 挂起当前 Goroutine 等待调度器的唤醒;
- 当调度器唤醒当前 Goroutine 时,会再次按照 lockOrder 遍历所有的 case,从中查找需要被处理的 runtime.sudog 对应的索引;
1
2
3
4
5
6
7
|
// Select case descriptor.
// Known to compiler.
// Changes here must also be made in src/cmd/internal/gc/select.go's scasetype.
type scase struct {
c *hchan // chan
elem unsafe.Pointer // data element
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
|
// selectgo implements the select statement.
//
// cas0 points to an array of type [ncases]scase, and order0 points to
// an array of type [2*ncases]uint16 where ncases must be <= 65536.
// Both reside on the goroutine's stack (regardless of any escaping in
// selectgo).
//
// For race detector builds, pc0 points to an array of type
// [ncases]uintptr (also on the stack); for other builds, it's set to
// nil.
//
// selectgo returns the index of the chosen scase, which matches the
// ordinal position of its respective select{recv,send,default} call.
// Also, if the chosen scase was a receive operation, it reports whether
// a value was received.
func selectgo(cas0 *scase, order0 *uint16, pc0 *uintptr, nsends, nrecvs int, block bool) (int, bool) {
if debugSelect {
print("select: cas0=", cas0, "\n")
}
// 1. 初始化
// NOTE: In order to maintain a lean stack size, the number of scases
// is capped at 65536.
cas1 := (*[1 << 16]scase)(unsafe.Pointer(cas0))
order1 := (*[1 << 17]uint16)(unsafe.Pointer(order0))
ncases := nsends + nrecvs
scases := cas1[:ncases:ncases]
pollorder := order1[:ncases:ncases]
lockorder := order1[ncases:][:ncases:ncases]
// NOTE: pollorder/lockorder's underlying array was not zero-initialized by compiler.
// Even when raceenabled is true, there might be select
// statements in packages compiled without -race (e.g.,
// ensureSigM in runtime/signal_unix.go).
var pcs []uintptr
if raceenabled && pc0 != nil {
pc1 := (*[1 << 16]uintptr)(unsafe.Pointer(pc0))
pcs = pc1[:ncases:ncases]
}
casePC := func(casi int) uintptr {
if pcs == nil {
return 0
}
return pcs[casi]
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
// The compiler rewrites selects that statically have
// only 0 or 1 cases plus default into simpler constructs.
// The only way we can end up with such small sel.ncase
// values here is for a larger select in which most channels
// have been nilled out. The general code handles those
// cases correctly, and they are rare enough not to bother
// optimizing (and needing to test).
// 首先会进行执行必要的初始化操作并决定处理 case 的两个顺序 — 轮询顺序 pollOrder 和加锁顺序 lockOrder
// generate permuted order
norder := 0
// 轮询顺序:通过 runtime.fastrandn 函数引入随机性;随机的轮询顺序可以避免 Channel 的饥饿问题,保证公平性;
for i := range scases {
cas := &scases[i]
// Omit cases without channels from the poll and lock orders.
// 当 case 不包含 Channel 时,会被跳过
if cas.c == nil {
cas.elem = nil // allow GC
continue
}
j := fastrandn(uint32(norder + 1))
pollorder[norder] = pollorder[j]
pollorder[j] = uint16(i)
norder++
}
pollorder = pollorder[:norder]
lockorder = lockorder[:norder]
// sort the cases by Hchan address to get the locking order.
// simple heap sort, to guarantee n log n time and constant stack footprint.
// 加锁顺序:按照 Channel 的地址排序后确定加锁顺序;根据 Channel 的地址顺序确定加锁顺序能够避免死锁的发生。
for i := range lockorder {
j := i
// Start with the pollorder to permute cases on the same channel.
c := scases[pollorder[i]].c
for j > 0 && scases[lockorder[(j-1)/2]].c.sortkey() < c.sortkey() {
k := (j - 1) / 2
lockorder[j] = lockorder[k]
j = k
}
lockorder[j] = pollorder[i]
}
for i := len(lockorder) - 1; i >= 0; i-- {
o := lockorder[i]
c := scases[o].c
lockorder[i] = lockorder[0]
j := 0
for {
k := j*2 + 1
if k >= i {
break
}
if k+1 < i && scases[lockorder[k]].c.sortkey() < scases[lockorder[k+1]].c.sortkey() {
k++
}
if c.sortkey() < scases[lockorder[k]].c.sortkey() {
lockorder[j] = lockorder[k]
j = k
continue
}
break
}
lockorder[j] = o
}
if debugSelect {
for i := 0; i+1 < len(lockorder); i++ {
if scases[lockorder[i]].c.sortkey() > scases[lockorder[i+1]].c.sortkey() {
print("i=", i, " x=", lockorder[i], " y=", lockorder[i+1], "\n")
throw("select: broken sort")
}
}
}
// lock all the channels involved in the select
// runtime.sellock 会按照之前生成的加锁顺序锁定 select 语句中包含所有的 Channel。
sellock(scases, lockorder)
// 2. 循环
var (
gp *g
sg *sudog
c *hchan
k *scase
sglist *sudog
sgnext *sudog
qp unsafe.Pointer
nextp **sudog
)
// pass 1 - look for something already waiting
// 循环执行的第一个阶段,查找已经准备就绪的 Channel。循环会遍历所有的 case 并找到需要被唤起的 runtime.sudog 结构,在这个阶段,我们会根据 case 的四种类型分别处理:
// 第一阶段的主要职责是查找所有 case 中是否有可以立刻被处理的 Channel。无论是在等待的 Goroutine 上还是缓冲区中,只要存在数据满足条件就会立刻处理.
var casi int
var cas *scase
var caseSuccess bool
var caseReleaseTime int64 = -1
var recvOK bool
// 查找是否已经存在准备就绪的 Channel,即可以执行收发操作
for _, casei := range pollorder {
casi = int(casei)
cas = &scases[casi]
c = cas.c
// 当 case 会从 Channel 中接收数据时
if casi >= nsends {
// 如果当前 Channel 的 sendq 上有等待的 Goroutine,就会跳到 recv 标签并从缓冲区读取数据后将等待 Goroutine 中的数据放入到缓冲区中相同的位置;
sg = c.sendq.dequeue()
// recv:可以从休眠的发送方获取数据;
if sg != nil {
goto recv
}
// 如果当前 Channel 的缓冲区不为空,就会跳到 bufrecv 标签处从缓冲区获取数据;
// bufrecv:可以从缓冲区读取数据;
if c.qcount > 0 {
goto bufrecv
}
// 如果当前 Channel 已经被关闭,就会跳到 rclose 做一些清除的收尾工作;
// rclose:可以从关闭的 Channel 读取 EOF;
if c.closed != 0 {
goto rclose
}
} else {
// 当 case 会向 Channel 发送数据时;
if raceenabled {
racereadpc(c.raceaddr(), casePC(casi), chansendpc)
}
// 如果当前 Channel 已经被关,闭就会直接跳到 sclose 标签,触发 panic 尝试中止程序;
// sclose:向关闭的 Channel 发送数据;
if c.closed != 0 {
goto sclose
}
// 如果当前 Channel 的 recvq 上有等待的 Goroutine,就会跳到 send 标签向 Channel 发送数据;
sg = c.recvq.dequeue()
// send:可以向休眠的接收方发送数据;
if sg != nil {
goto send
}
// 如果当前 Channel 的缓冲区存在空闲位置,就会将待发送的数据存入缓冲区;
// bufsend:可以向缓冲区写入数据;
if c.qcount < c.dataqsiz {
goto bufsend
}
}
}
// 当 select 语句中包含 default 时;
// 表示前面的所有 case 都没有被执行,这里会解锁所有 Channel 并返回,意味着当前 select 结构中的收发都是非阻塞的;
// retc:结束调用并返回;
if !block {
selunlock(scases, lockorder)
casi = -1
goto retc
}
// pass 2 - enqueue on all chans
// 如果不能立刻找到活跃的 Channel 就会进入循环的下一阶段,按照需要将当前 Goroutine 加入到 Channel 的 sendq 或者 recvq 队列中:
gp = getg()
if gp.waiting != nil {
throw("gp.waiting != nil")
}
nextp = &gp.waiting
// 除了将当前 Goroutine 对应的 runtime.sudog 结构体加入队列之外,这些结构体都会被串成链表附着在 Goroutine 上。在入队之后会调用 runtime.gopark 挂起当前 Goroutine 等待调度器的唤醒。
for _, casei := range lockorder {
casi = int(casei)
cas = &scases[casi]
c = cas.c
sg := acquireSudog()
sg.g = gp
sg.isSelect = true
// No stack splits between assigning elem and enqueuing
// sg on gp.waiting where copystack can find it.
// 在 gp.waiting 上分配 elem 和入队 sg 之间没有栈分段,copystack 可以在其中找到它。
sg.elem = cas.elem
sg.releasetime = 0
if t0 != 0 {
sg.releasetime = -1
}
sg.c = c
// Construct waiting list in lock order.
// 按锁的顺序创建等待链表
*nextp = sg
nextp = &sg.waitlink
if casi < nsends {
c.sendq.enqueue(sg)
} else {
c.recvq.enqueue(sg)
}
}
// wait for someone to wake us up
// 等待被唤醒
gp.param = nil
// Signal to anyone trying to shrink our stack that we're about
// to park on a channel. The window between when this G's status
// changes and when we set gp.activeStackChans is not safe for
// stack shrinking.
atomic.Store8(&gp.parkingOnChan, 1)
// selparkcommit 根据等待列表依次解锁
gopark(selparkcommit, nil, waitReasonSelect, traceEvGoBlockSelect, 1)
//等到 select 中的一些 Channel 准备就绪之后,当前 Goroutine 就会被调度器唤醒。这时会继续执行 runtime.selectgo 函数的第三部分,从 runtime.sudog 中读取数据:
// 第三次遍历全部 case 时,我们会先获取当前 Goroutine 接收到的参数 sudog 结构,我们会依次对比所有 case 对应的 sudog 结构找到被唤醒的 case,获取该 case 对应的索引并返回。
gp.activeStackChans = false
// 重新上锁
sellock(scases, lockorder)
gp.selectDone = 0
sg = (*sudog)(gp.param)
gp.param = nil
// pass 3 - dequeue from unsuccessful chans
// otherwise they stack up on quiet channels
// record the successful case, if any.
// We singly-linked up the SudoGs in lock order.
// pass 3 - 从不成功的 channel 中出队
// 否则将它们堆到一个安静的 channel 上并记录所有成功的分支
// 我们按锁的顺序单向链接 sudog
casi = -1
cas = nil
caseSuccess = false
sglist = gp.waiting
// Clear all elem before unlinking from gp.waiting.
// 从 gp.waiting 取消链接之前清除所有的 elem
for sg1 := gp.waiting; sg1 != nil; sg1 = sg1.waitlink {
sg1.isSelect = false
sg1.elem = nil
sg1.c = nil
}
gp.waiting = nil
for _, casei := range lockorder {
k = &scases[casei]
if sg == sglist {
// sg has already been dequeued by the G that woke us up.
// sg 已经被唤醒我们的 G 出队了。
casi = int(casei)
cas = k
caseSuccess = sglist.success
if sglist.releasetime > 0 {
caseReleaseTime = sglist.releasetime
}
} else {
c = k.c
if int(casei) < nsends {
c.sendq.dequeueSudoG(sglist)
} else {
c.recvq.dequeueSudoG(sglist)
}
}
// 由于当前的 select 结构找到了一个 case 执行,那么剩下 case 中没有被用到的 sudog 就会被忽略并且释放掉。为了不影响 Channel 的正常使用,我们还是需要将这些废弃的 sudog 从 Channel 中出队。
sgnext = sglist.waitlink
sglist.waitlink = nil
releaseSudog(sglist)
sglist = sgnext
}
if cas == nil {
throw("selectgo: bad wakeup")
}
c = cas.c
if debugSelect {
print("wait-return: cas0=", cas0, " c=", c, " cas=", cas, " send=", casi < nsends, "\n")
}
if casi < nsends {
if !caseSuccess {
goto sclose
}
} else {
recvOK = caseSuccess
}
if raceenabled {
if casi < nsends {
raceReadObjectPC(c.elemtype, cas.elem, casePC(casi), chansendpc)
} else if cas.elem != nil {
raceWriteObjectPC(c.elemtype, cas.elem, casePC(casi), chanrecvpc)
}
}
if msanenabled {
if casi < nsends {
msanread(cas.elem, c.elemtype.size)
} else if cas.elem != nil {
msanwrite(cas.elem, c.elemtype.size)
}
}
selunlock(scases, lockorder)
goto retc
// 当我们在循环中发现缓冲区中有元素或者缓冲区未满时就会通过 goto 关键字跳转到 bufrecv 和 bufsend 两个代码段,这两段代码的执行过程都很简单,它们只是向 Channel 中发送数据或者从缓冲区中获取新数据:
// 这里在缓冲区进行的操作和直接调用 runtime.chansend 和 runtime.chanrecv 差不多,上述两个过程在执行结束之后都会直接跳到 retc 字段。
bufrecv:
// can receive from buffer
if raceenabled {
if cas.elem != nil {
raceWriteObjectPC(c.elemtype, cas.elem, casePC(casi), chanrecvpc)
}
racenotify(c, c.recvx, nil)
}
if msanenabled && cas.elem != nil {
msanwrite(cas.elem, c.elemtype.size)
}
recvOK = true
qp = chanbuf(c, c.recvx)
if cas.elem != nil {
typedmemmove(c.elemtype, cas.elem, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
selunlock(scases, lockorder)
goto retc
bufsend:
// can send to buffer
if raceenabled {
racenotify(c, c.sendx, nil)
raceReadObjectPC(c.elemtype, cas.elem, casePC(casi), chansendpc)
}
if msanenabled {
msanread(cas.elem, c.elemtype.size)
}
typedmemmove(c.elemtype, chanbuf(c, c.sendx), cas.elem)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
selunlock(scases, lockorder)
goto retc
// 两个直接收发 Channel 的情况会调用运行时函数 runtime.send 和 runtime.recv,这两个函数会与处于休眠状态的 Goroutine 打交道:
recv:
// can receive from sleeping sender (sg)
recv(c, sg, cas.elem, func() { selunlock(scases, lockorder) }, 2)
if debugSelect {
print("syncrecv: cas0=", cas0, " c=", c, "\n")
}
recvOK = true
goto retc
send:
// can send to a sleeping receiver (sg)
if raceenabled {
raceReadObjectPC(c.elemtype, cas.elem, casePC(casi), chansendpc)
}
if msanenabled {
msanread(cas.elem, c.elemtype.size)
}
send(c, sg, cas.elem, func() { selunlock(scases, lockorder) }, 2)
if debugSelect {
print("syncsend: cas0=", cas0, " c=", c, "\n")
}
goto retc
retc:
if caseReleaseTime > 0 {
blockevent(caseReleaseTime-t0, 1)
}
return casi, recvOK
//不过如果向关闭的 Channel 发送数据或者从关闭的 Channel 中接收数据,情况就稍微有一点复杂了:
// 1. 从一个关闭 Channel 中接收数据会直接清除 Channel 中的相关内容;
// 2. 向一个关闭的 Channel 发送数据就会直接 panic 造成程序崩溃:
rclose:
// read at end of closed channel
selunlock(scases, lockorder)
recvOK = false
if cas.elem != nil {
typedmemclr(c.elemtype, cas.elem)
}
if raceenabled {
raceacquire(c.raceaddr())
}
goto retc
sclose:
// send on closed channel
selunlock(scases, lockorder)
panic(plainError("send on closed channel"))
}
|
总体来看,select 语句中的 Channel 收发操作和直接操作 Channel 没有太多出入,只是由于 select 多出了 default 关键字所以会支持非阻塞的收发。
1
2
3
4
5
6
7
8
9
10
|
func sellock(scases []scase, lockorder []uint16) {
var c *hchan
for _, o := range lockorder {
c0 := scases[o].c
if c0 != c {
c = c0
lock(&c.lock)
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func selunlock(scases []scase, lockorder []uint16) {
// We must be very careful here to not touch sel after we have unlocked
// the last lock, because sel can be freed right after the last unlock.
// Consider the following situation.
// First M calls runtime·park() in runtime·selectgo() passing the sel.
// Once runtime·park() has unlocked the last lock, another M makes
// the G that calls select runnable again and schedules it for execution.
// When the G runs on another M, it locks all the locks and frees sel.
// Now if the first M touches sel, it will access freed memory.
for i := len(lockorder) - 1; i >= 0; i-- {
c := scases[lockorder[i]].c
if i > 0 && c == scases[lockorder[i-1]].c {
continue // will unlock it on the next iteration
}
unlock(&c.lock)
}
}
|
参考
6.4 Channel
3.6 通信原语
5.2 select