使用jemalloc在Go中手动管理内存
文章目录
前言
Dgraph实验室自2015年成立以来一直是Go语言的用户。五年过去了,200K行的Go代码,我们很高兴地告诉大家,我们仍然相信Go是并且仍然是正确的选择。我们对Go的兴奋已经超越了构建系统,甚至导致我们用Go写脚本,而这些脚本通常是用Bash或Python编写的。我们发现,使用Go帮助我们建立了一个干净、可读、可维护的代码库,而且–最重要的是–高效和并发的代码库。
然而,有一个领域是我们从早期就关注的:内存管理。我们并不反对Go垃圾收集器,但尽管它为开发者提供了便利,它却有着与其他内存垃圾收集器相同的问题:它根本无法与手动内存管理的效率竞争。
当你手动管理内存时,内存使用量较低,可预测,并允许突发的内存分配,不会导致内存使用量的疯狂飙升。对于使用Go内存的Dgraph来说,所有这些都是一个问题1。事实上,Dgraph的内存耗尽是我们从用户那里听到的一个非常普遍的抱怨。
像Rust这样的语言一直在不断壮大,部分原因是它允许安全的手动内存管理。我们完全可以理解这一点。
根据我们的经验,进行手动内存分配和追寻潜在的内存泄漏比在有垃圾收集的语言中优化内存使用要花更少的精力2。在建立几乎能够无限扩展的数据库系统时,手动内存管理是非常值得的。
我们对Go的热爱和避免Go GC的需要,使我们找到了在Go中进行手动内存管理的新方法。当然,大多数Go用户永远不需要进行手动内存管理;除非你需要,否则我们建议不要这样做。当你需要的时候,你就会知道。
在这篇文章中,我将分享我们在Dgraph实验室对手动内存管理的探索中所学到的东西,并解释我们如何在Go中手动管理内存。
通过Cgo创建内存
灵感来自于Cgo wiki中关于将C数组转化为Go分片的部分。我们可以使用malloc在C语言中分配内存,并使用unsafe将其传递给Go,不受Go GC的干扰。
|
|
然而,上述做法有一个注意事项,正如golang.org/cmd/cgo中指出的。
注意:目前的实现有一个错误。虽然Go代码允许向C内存写入nil或C指针(但不是Go指针),但如果C内存的内容看起来是Go指针,当前的实现有时会导致运行时错误。因此,如果Go代码要在其中存储指针值,请避免将未初始化的C内存传递给Go代码。在将C语言的内存传递给Go之前,先将其清零。
因此,我们不使用malloc,而是使用其稍贵的兄弟姐妹,calloc。calloc的工作方式与malloc相同,只是在将内存返回给调用者之前将其清零。
我们一开始只是实现了基本的Calloc和Free函数,它们通过Cgo为Go分配和取消分配字节片。为了测试这些函数,我们开发并运行了一个连续的内存使用测试。这个测试无休止地重复着一个分配/取消分配的循环,首先分配各种随机大小的内存块,直到分配了16GB的内存,然后释放这些内存块,直到只剩下1GB的内存分配。
这个程序的C语言等价物的表现和预期的一样。我们会看到htop中的RSS内存增加到16GB,然后下降到1GB,又增加到16GB,如此循环。然而,使用Calloc和Free的Go程序在每个周期后都会逐渐使用更多的内存(见下图)。
我们将这一行为归因于默认的C.calloc调用中缺乏线程意识而导致的内存碎片化。经过Go #dark-arts Slack频道的一些帮助(特别感谢Kale Blankenship),我们决定给jemalloc一个尝试。
jemalloc
jemalloc 是一个通用的 malloc(3) 实现,强调避免碎片化和可扩展的并发支持。jemalloc 在 2005 年首次作为 FreeBSD 的 libc 分配器投入使用,从那时起,它已经进入了许多依赖其可预测行为的应用程序。- http://jemalloc.net
我们将我们的API转换为使用jemalloc3来调用和释放。它的表现非常好:jemalloc原生支持线程,几乎不存在内存碎片。我们的内存使用监控测试中的分配-分配周期在预期的限制之间循环,忽略了运行测试所需的少量开销。
为了确保我们使用的是jemalloc并避免名称冲突,我们在安装时添加了一个je_前缀,所以我们的API现在调用的是je_calloc和je_free,而不是calloc和free。
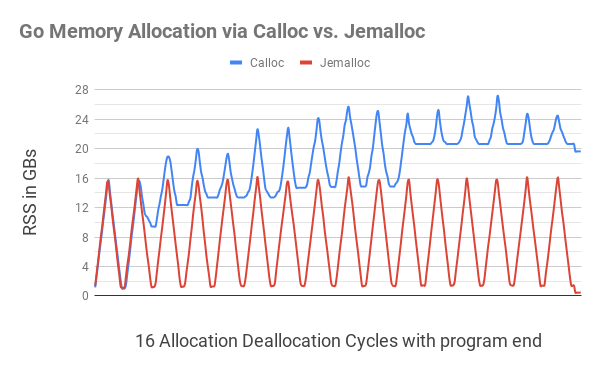
在上图中,通过C.calloc分配Go内存导致了严重的内存碎片化,导致程序在第11个周期时占用了20GB的内存。使用jemalloc的同等代码没有明显的碎片化,每个周期都会减少接近1GB。
在程序结束时(最右边的小点),在所有分配的内存被释放后,C.calloc程序仍然占用不到20GB的内存,而jemalloc显示400MB的内存使用率。
要安装jemalloc,请从这里下载它,然后运行以下命令。
|
|
整个Calloc代码看起来是这样的。
|
|
我们将这段代码作为Ristretto的z包的一部分,所以Dgraph和Badger都可以使用它。为了让我们的代码切换到使用jemalloc来分配字节片,我们添加了一个构建标签jemalloc。为了进一步简化我们的部署,我们通过设置正确的LDFLAGS,使jemalloc库静态链接到任何生成的Go二进制文件中。
在byte slices上布置 Go 结构
现在我们有了分配和释放字节片的方法,下一步就是用它来布局Go结构。我们可以从一个基本结构开始(完整代码)。
|
|
在上面的代码中,我们使用newNode在C分配的内存上布置了一个Go结构。我们创建了一个相应的freeNode函数,一旦我们完成了该结构,它就可以释放内存。Go结构的基本数据类型是int,还有一个指向下一个节点结构的指针,所有这些都是在程序中设置和访问的。我们分配了2M个节点对象,并从这些对象中创建了一个链接列表,以演示jemalloc的正常运作。
在默认的Go内存中,我们看到为带有2M个对象的链表分配了31MB的堆,但没有通过jemalloc分配任何东西。
|
|
使用jemalloc构建标签,我们看到通过jemalloc分配了30 MiB的内存,在释放了链表之后,这个数字下降到了0。Go的堆分配只有很小的399 KiB,这可能来自于运行程序的开销。
|
|
用Allocator摊派Calloc的成本
上面的代码对于避免通过Go分配内存非常有效。但是,这也是有代价的:降低性能。用时间来运行这两个实例,我们看到在没有jemalloc的情况下,程序运行了1.15秒。而使用jemalloc,则慢了5倍,为5.29秒。
|
|
我们将较慢的性能归因于每次分配内存时都要进行Cgo调用,而每次Cgo调用都会带来一些开销。为了解决这个问题,我们在ristretto/z包中写了一个Allocator库。这个库在一次调用中分配了较大的内存块,然后可以用来分配许多小对象,避免了昂贵的Cgo调用。
Allocator从一个缓冲区开始,当用尽时,会创建一个新的两倍大小的缓冲区。它维护一个所有分配的缓冲区的内部列表。最后,当用户用完数据后,他们可以调用Release来一次性释放所有这些缓冲区。注意,Allocator不做任何内存移动。这有助于确保我们拥有的任何结构指针保持有效。
虽然这可能看起来有点像tcmalloc/jemalloc使用的板块式内存管理,但这要简单得多。一旦分配,你不能只释放一个结构。你只能释放Allocator4使用的所有内存。
Allocator做得很好,它可以廉价地布局数百万个结构,并在完成后释放它们,而不涉及Go堆。上图所示的同一个程序,在使用新的分配器构建标签运行时,运行速度甚至比Go内存版本更快。
|
|
从Go 1.14开始,-race标志开启了结构体的内存对齐检查。Allocator有一个AllocateAligned方法,它返回的内存以正确的指针对齐方式开始,以通过这些检查。根据结构体的大小,这可能会导致一些内存浪费,但由于字的边界正确,使得CPU指令更加高效。
我们面临着另一个内存管理问题:有时内存分配发生在一个与取消分配非常不同的地方。这两个地方之间的唯一交流可能是分配的结构,而没有办法向下传递实际的分配器对象。为了处理这个问题,我们给每个Allocator对象分配一个唯一的ID,这些对象存储在一个uint64引用中。每个新的Allocator对象都被存储在一个全局map上,与它的引用相对应。然后,Allocator对象可以使用这个引用被调用,并在不再需要数据的时候被释放。
明智的引用
不要从手动分配的内存中引用Go分配的内存。
如上图所示,手动分配结构时,必须确保结构中没有对Go分配的内存的引用。请考虑对上面的结构稍作修改。
|
|
让我们使用上面定义的root := newNode(val) func来手动分配一个节点。然而,如果我们再设置root.next = &node{val: val},通过Go内存分配链接列表中的所有其他节点,我们必然会出现以下分段故障。
|
|
Go分配的内存被垃圾回收,因为没有有效的Go结构指向它。只有C分配的内存在引用它,而Go堆中没有任何对它的引用,导致了上述故障。因此,如果您创建了一个结构并手动分配了内存,那么必须确保所有可递归访问的字段也是手动分配的。
例如,如果上述结构使用的是字节片,我们也要使用Allocator分配该字节片,以避免Go内存与C内存混合。
|
|
处理GB级分配的问题
Allocator对于手动分配数以百万计的结构是非常好的。然而,我们有一些用例需要创建数十亿的小对象并对它们进行排序。在Go中,即使使用Allocator,也会有这样的方式。
|
|
所有这些1B节点都是在分配器上手动分配的,这就变得很昂贵。我们还需要支付Go中分片的费用,8GB的内存(每个节点指针8字节,1B条目)本身就很昂贵。
为了处理这类用例,我们建立了z.Buffer,它可以在文件上进行内存映射,允许Linux按照系统的要求对内存进行分页。它实现了io.Writer,取代了我们对byte.Buffer的依赖。
更重要的是,z.Buffer提供了一种新的方式来分配较小的数据片。通过调用SliceAllocate(n),z.Buffer会写出被分配的片断的长度(n),然后再分配片断。这使得z.Buffer能够理解片断的边界,并通过SliceIterate正确地迭代它们。
对可变长度的数据进行排序
对于排序,我们最初试图从z.Buffer中获得片断,访问片断进行比较,但只对片断进行排序。给定一个偏移量,z.Buffer可以读取偏移量,找到切片的长度并返回该切片。因此,这个系统允许我们按照排序的顺序访问切片,而不产生任何内存移动。虽然很新颖,但这种机制给内存带来了很大的压力,因为我们仍然要为将这些偏移量带入Go内存而支付8GB的内存罚款。
我们有一个关键的限制,那就是片断的大小不一样。此外,我们只能按顺序访问这些片断,而不能按反向或随机顺序访问,而不能事先计算和存储偏移量。大多数就地排序算法都假定值的大小是相同的5,可以随机访问,并且可以随时调换。Go的sort.Slice也是这样工作的,因此并不适合z.Buffer。
在这些限制下,我们发现合并排序算法是最适合这项工作的。通过合并排序,我们可以按顺序对缓冲区进行操作,只需要在缓冲区的大小上多占用一半的内存。事实证明,这不仅比将偏移量带入内存更便宜,而且在内存使用开销方面也更可预测(大约是缓冲区大小的一半)。更妙的是,运行合并排序所需的开销本身就是内存映射的。
合并排序也有一个非常积极的影响。在基于偏移量的排序中,我们必须将偏移量保留在内存中,同时对缓冲区进行迭代和处理,这对内存造成了更大压力。有了合并排序,所需的额外内存在迭代开始时就被释放,这意味着有更多的内存可用于缓冲区处理。
z.Buffer还支持通过Calloc分配内存,一旦超过了用户指定的某个限制,就自动进行内存映射。这使得它在所有大小的数据中都能很好地工作。
|
|
捕捉内存泄漏
如果不触及内存泄漏,所有这些讨论都是不完整的。现在我们正在使用手动内存分配,必然会有内存泄漏,因为我们忘记了去分配内存。我们怎样才能抓住这些问题呢?
我们早期做的一件简单的事情是让一个原子计数器跟踪通过这些调用分配的字节数,所以我们可以通过z.NumAllocBytes()快速知道我们在程序中手动分配了多少内存。如果在我们的内存测试结束时,我们仍有剩余的内存,这表明有泄漏。
当我们确实发现泄漏时,我们最初试图使用jemalloc内存分析器。但是,我们很快意识到,这并没有什么帮助。由于Cgo边界的存在,它不能看到整个调用堆栈。剖析器所看到的是来自相同的z.Calloc和z.Free调用的分配和取消分配。
感谢Go运行时,我们能够快速建立一个简单的系统来捕获进入z.Calloc的调用者,并将其与z.Free调用相匹配。这个系统需要mutex锁,所以我们选择不默认启用它。相反,我们使用一个泄漏构建标志,为我们的开发构建打开泄漏调试信息。这将自动检测泄漏,并打印出任何泄漏发生的地方。
|
|
|
|
结论
通过这些技术,我们得到了两全其美的结果:我们可以在关键的、受内存约束的代码路径中进行手动内存分配。同时,我们可以在非关键的代码路径中获得自动垃圾收集的好处。即使你不习惯使用Cgo或jemalloc,你也可以在更大块的Go内存上应用这些技术,产生类似的影响。
上面提到的所有库都可以在Apache 2.0许可下在Ristretto/z包中获得。memtest和演示代码位于contrib文件夹中。
Badger和Dgraph(尤其是Badger)都已经从使用这些库中获得了巨大的收益。我们现在可以用有限的内存使用量来处理数千兆字节的数据–与你对C++程序的期望一致。我们正在进一步识别对Go内存造成压力的地方,并在有意义的地方通过切换到手动内存管理来缓解压力。
Dgraph v20.11(T’Challa)版本将是第一个包含所有这些内存管理功能的版本。我们的目标是确保Dgraph在运行任何种类的工作负载时都不需要超过32GB的物理内存。而使用z.Calloc、z.Free、z.Allocator和z.Buffer有助于我们用Go实现这一目标。
转载
文章作者 Forz
上次更新 2021-09-11